Pytorch - 2 Model Parallel
Continue Pytorch notes with Single-Machine Model Parallel.
Model Parallel
When the model is too large to fit into a single GPU, model parallel is necessary. The key is to sent different part of the network to different GPUs.
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
#`net1` and `net2` are sent to GPU 0 and 1
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
# Training data are also sent to GPU 0 for net 1
x = self.relu(self.net1(x.to('cuda:0')))
# and data after ReLU is sent to GPU 1 before calling net2
return self.net2(x.to('cuda:1'))
When call this model, you need to make sure lables are on the same devices as the output
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = model(torch.randn(20, 10))
# Labels are sent to GPU 1 as net2
labels = torch.randn(20, 5).to('cuda:1')
loss_fn(outputs, labels).backward()
optimizer.step()
To use on existing models, just take different part of the network into different GPUs.
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
self.layer1,
self.layer2
).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
# tensor.view change tensor shape
return self.fc(x.view(x.size(0), -1))
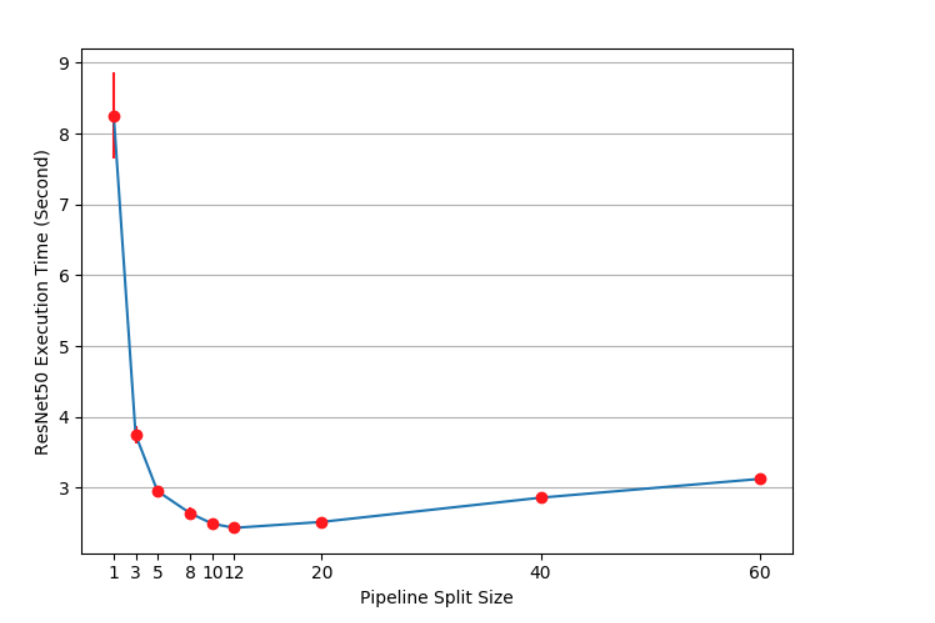
But one of the GPUs are working while the other one is alway idle. So the performance is actually worse. We can designa a pipeline workflow to solve this issue.
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
## The network defination keeps the same
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
## Make the forward a pipeline
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. ``s_prev`` runs on ``cuda:1``
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. ``s_next`` runs on ``cuda:0``, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
You can also loop over different split size to get the best performances. (12 is the winner here)