RL in 2025
Happy $\pi$ Day! It’s time to review RL in 2025. This zhihu gives me a much clear review of value based and policy based methods. I guess the yearly review on RL also improves my understanding of RL
1 $\pi$ vs $V_\pi$
RL can be summarized as two steps
- Value evaluation: Given a policy $\pi$, how to correctly evaludate current value function $V_\pi$
- Policy iteration: Given a current value function $V_\pi$, how to improve policy $\pi$
We perform these two steps in turn till converge and get the best policy $\pi^$ and best value function $V_\pi^$
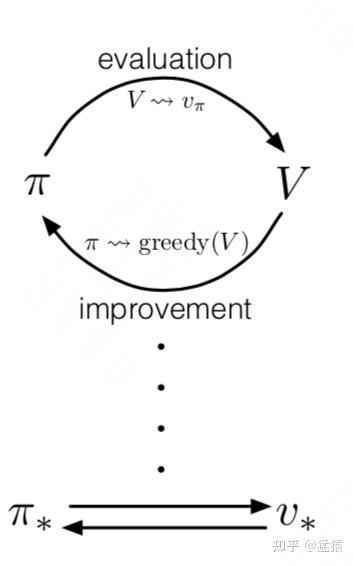
Hence we can define value-based and policy-based method accordinng, or actor-critic for use it together.

2 Policy based RL
The policy based RL has the following target
 Going through some derivaties and remove items has zero derivate to policy(only $s$ related terms), we get following gradient
Going through some derivaties and remove items has zero derivate to policy(only $s$ related terms), we get following gradient

Here are the different variances of this gradient based on different $\Psi$ defination.

- What we dicussed so far is using the sum of all rewards along the trajectory.
- This is the causal version, which only consider rewards after time t
- Introduce a baseline to consider relative quality of the rewards instead of abosolute values.
- Q-function, namely action-value function $Q(s_t,a_t)$, is the average of values of all trajectory from $s_t$ after taking action $a_t$
- Advangtage function, $A(s_t,a_t)=Q(s_t,a_t)-V(s_t)$. Here value function $V(s_t)$, state-value function, is the the average of values of all trajectory from $s_t$, taking all possible actions.
 6。 TD error, temporal difference method is based on expectation formular for Q and V function.
6。 TD error, temporal difference method is based on expectation formular for Q and V function.
 Advtange function is the expections of TD errors
Advtange function is the expections of TD errors
