Reinforcement Learning - PPO
PPO, Proximal Policy Optimizatoin. One of the most powerful RL algorithm, and the default RL training algorithm by OpenAI.
It all starts with on-policy strategy moves to off-policy. One good example here from 棋魂 to demonstrate the difference of these two.

The advantage of moving to off-policy is obvious, sample data can be reused with the fixed policy $\pi_{\theta’}$ while you are updating parameter $\theta$. And a math trick called importance sampling is introduced, which is very straigtforward.

Here is how we use the trick in the deduction, and Bayes rule, of course. $p_\theta(s_t)$ and $p_{\theta’}(s_t)$ are cancelled out, NOT because they are equall, just because we can not calculate the probablity of certain states. Then we can get the objective function $J^{\theta’}(\theta)$ by reversing the gradient.
- $\theta$ is the parameter we are going to update
- $\theta’$ is the fixed parameter we used to sample

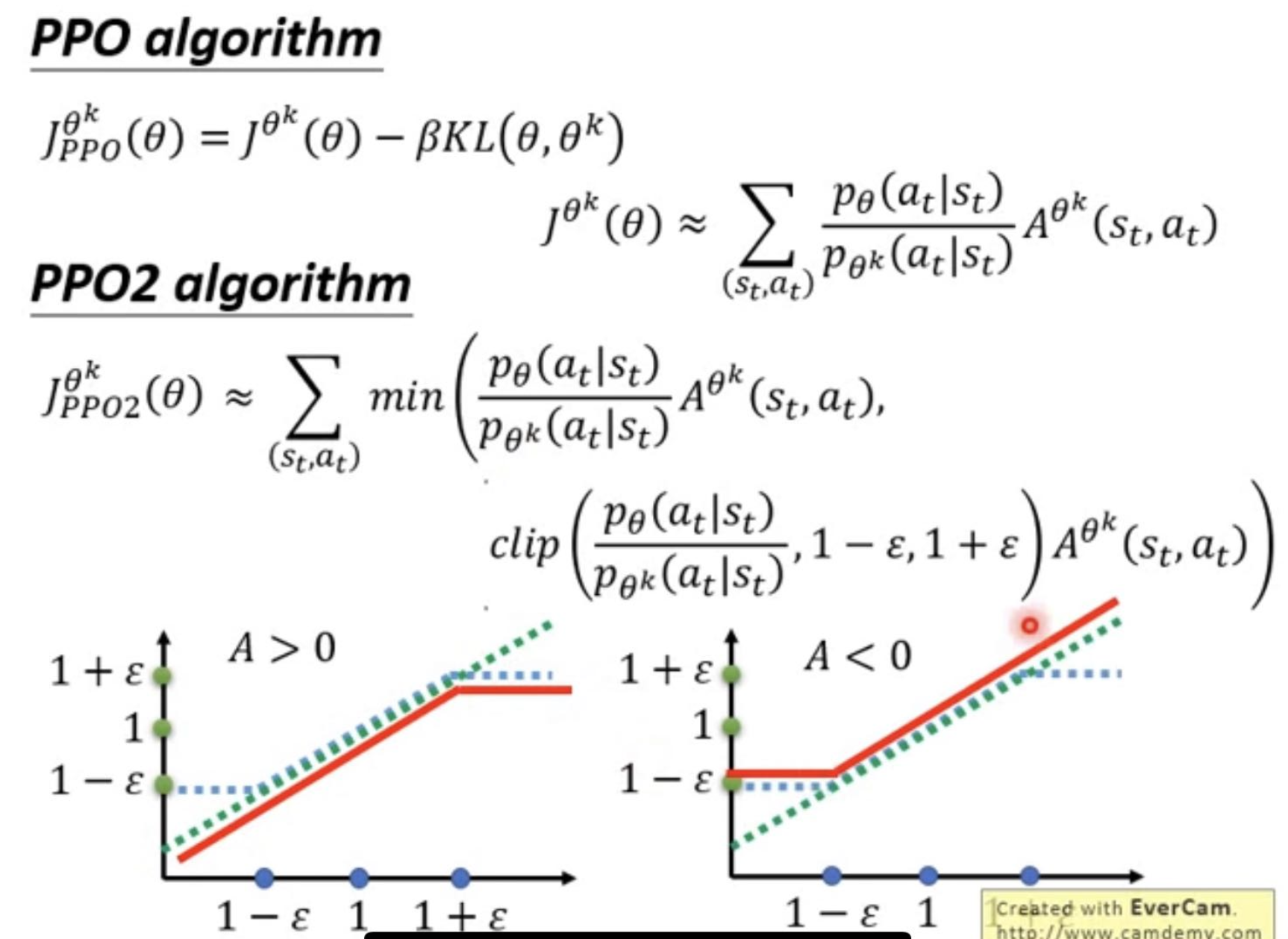
So now you basically already get the formula for PPO, which under one condition is that for importance sampling to work, two distribution $p$ and $q$ need to be close distributions. So we use KL divergence to regulate the objective function. TRPO is similar.

Again, here is the full implementation of PPO.

and imporved PPO with clipping. (The red line is the return value of the clip function)