RL 2024-2
Review some basic concepts in RL from this blog
A good paper on it as well
On/Off Policy Reference here
1 Think LLM in RL
Policy: LLM
State: input, a textual sequence
Action: The next token
New state: texual sequence with an added token

2 Important terms
- Trajectory: sequence of
statesandactions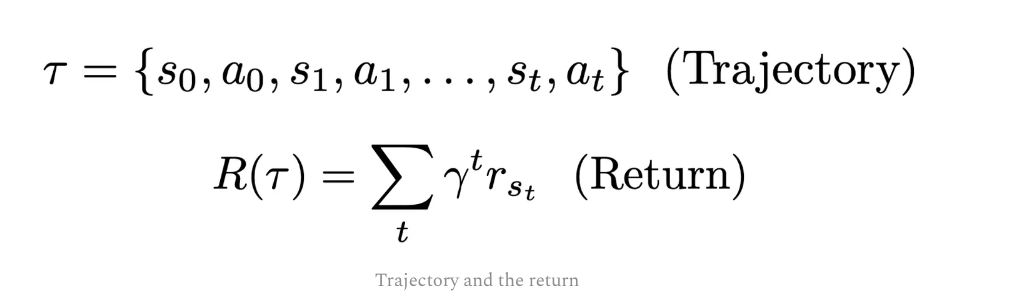
- Episode: the trajectory from start state to end state
-
Return: rewards summed over an entire trajectory
-
Online vs Offline RL
Online: data is acuqired interactively Offline: use pre-recorded dataset -
On vs Off- Policy
This is only meaningful in the context of online RL. Offline RL always employs an off-policy learing scheme.(the training dataset trains an optimal policy irrespective of the policy used to generate data)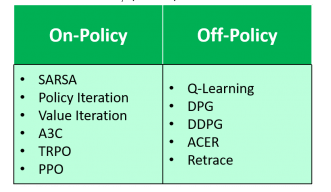
Target policy: $\pi(a s)$ the policy our agent is aiming to learn. Agent is learning value function for this policy. Behavior policy: $b(a|s)$ the policy that is being used by the agent to select actions as it interacts with the environment. Agent follows this policy to interact with the environment.
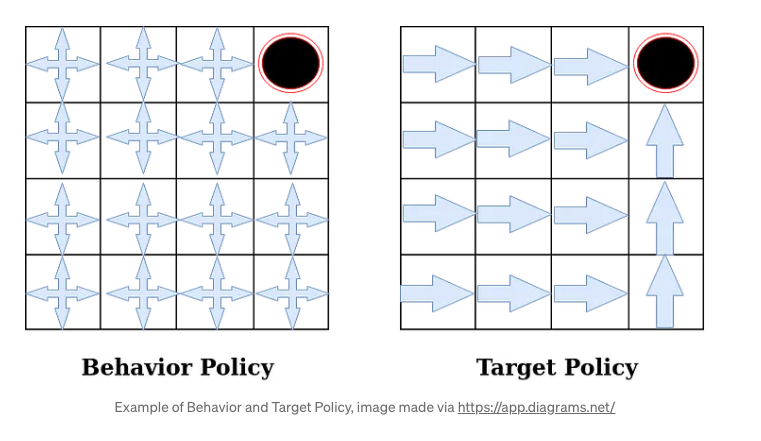
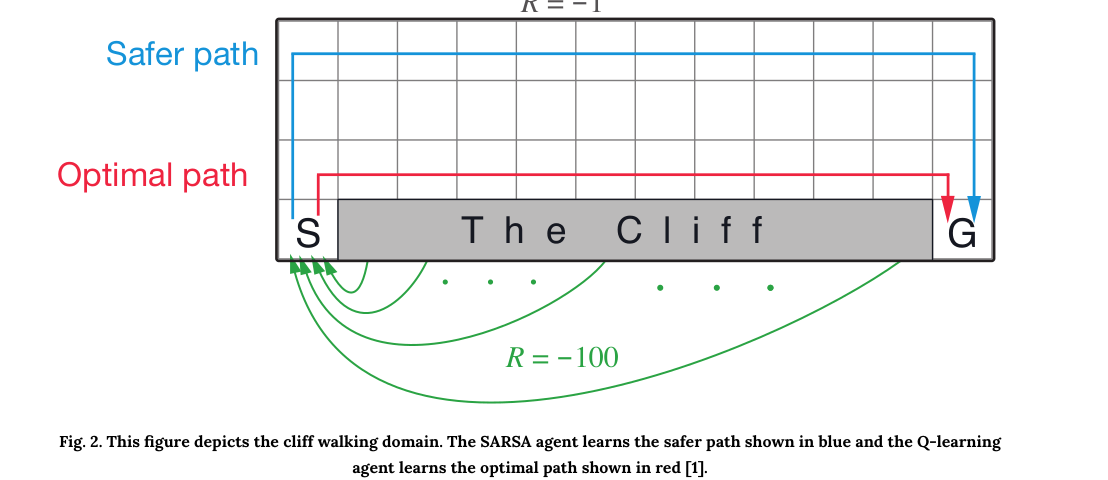
On Policy: target policy == behavior policy (SARSA)
 Off Policy: target policy != behavior policy (Q-Learning)
Off Policy: target policy != behavior policy (Q-Learning)

On Policy may choose a safer path(assume that the cliff walking agent will at times jump over the cliff if it travels too close to the edge), and have higher rewards. Off policy may choose the optimal path (greedy approach, assuming agent act optimally in the future and NOT to jump off cliff)
-
Model-based vs. Model-free
Model-based: has an agent trying to understand its environment and creating a model for it based on its interactions with this environment. preferences take priority over the consequences of the actions Monte-Carlo Tree Search (MCTS) is model based method
model-free: It seeks to learn the consequences of their actions through experience via algorithms such as Policy Gradient, Q-Learning, etc. It carries out an action multiple times and will adjust the policy for optimal rewards, based on the outcomes.
On-policy and off-policy learning fall under the category of model-free reinforcement learning algorithms, meaning that we do not have access to the transition probability distribution.
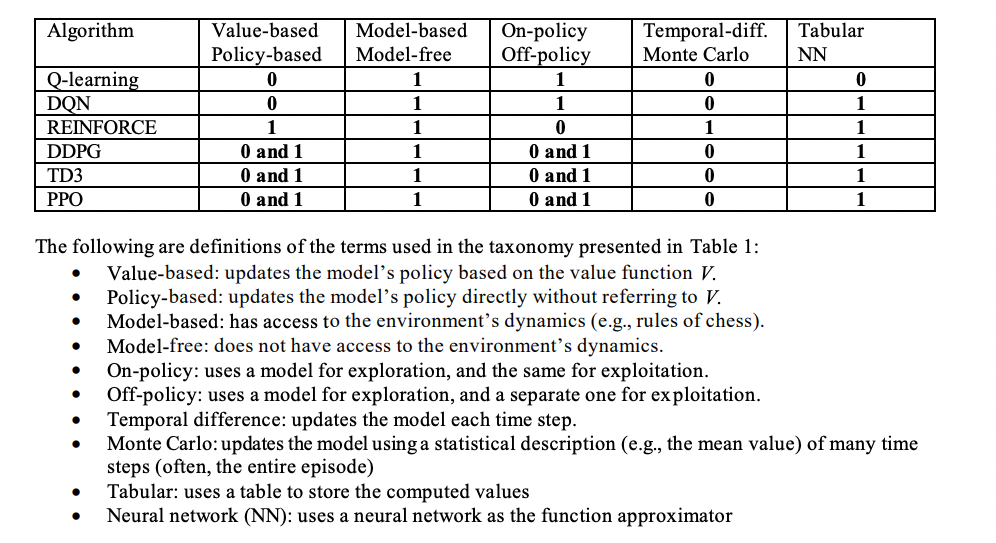
Summary:
3 Q-Learning
- Bellman equation
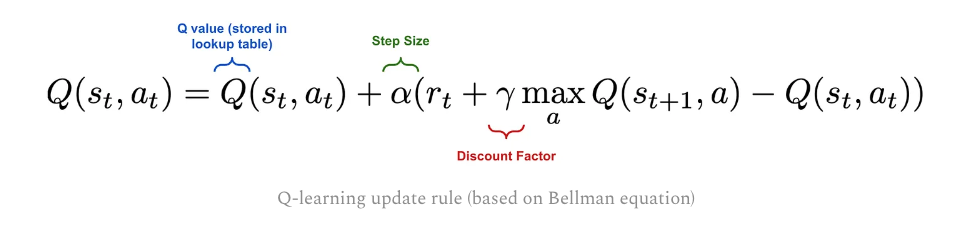
and python implementation is heredef choose_action(state): action=0 if np.random.uniform(0, 1) < epsilon: action = env.action_space.sample() else: action = np.argmax(Q[state, :]) return action ## In the learning loop ## The action here is NOT always greedy step which used in the last round of Q update action = choose_action(current_state) Q_table[current_state, action] = (1-lr) * Q_table[current_state, action] +lr*(reward + gamma*max(Q_table[next_state,:]))Due to $\epsilon$-greedy policy, we may not always use the greedy policy result, so it’s off-policy learning algorithem. But in SARSA,
action2, which is used to update Q, is passed into the next loop to get the new state. - SARSA
#Function to learn the Q-value
def update(state, state2, reward, action, action2):
predict = Q[state, action]
target = reward + gamma * Q[state2, action2]
Q[state, action] = Q[state, action] + alpha * (target - predict)
### In the learning loop
#Getting the next state. The action1 here is EXACTLY actions2 used to in the last round of Q udpate
state2, reward, done, info = env.step(action1)
#Choosing the next action
action2 = choose_action(state2)
#Learning the Q-value
update(state1, state2, reward, action1, action2)
state1 = state2
action1 = action2
4 DQL
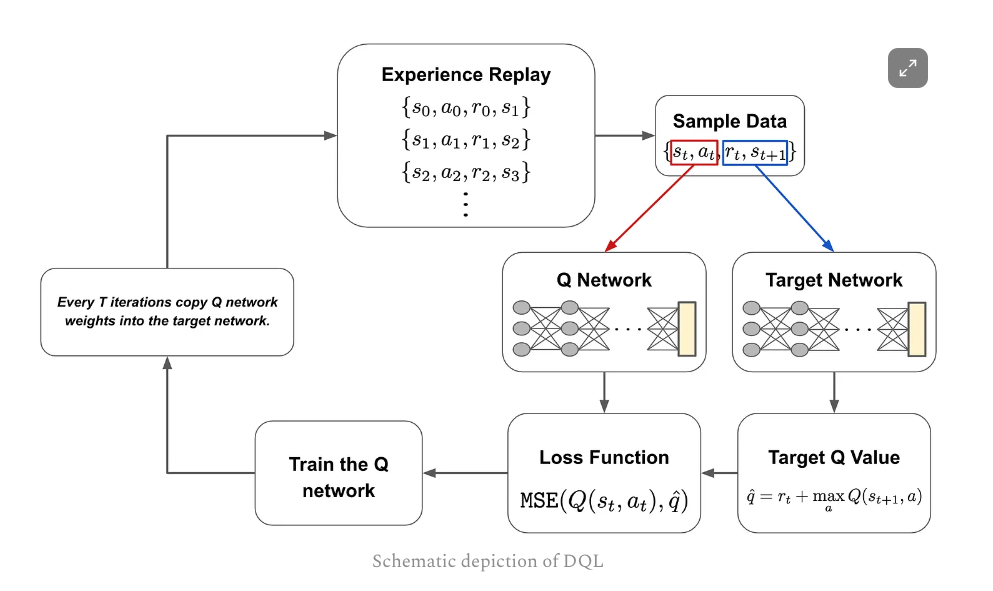
- experience replay The process of gathering interaction data for training the Q network
-
Q Network Keep updating Q network by backpropgate the loss function
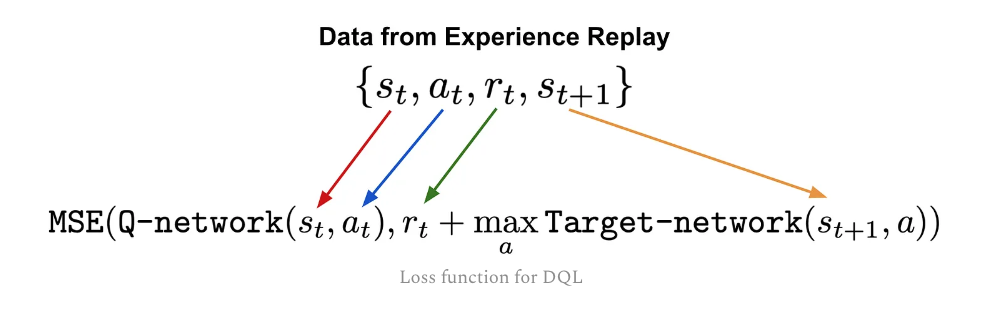 In vanilla Q learning, we have two Q values as well
Q(s, a) for current state-action and $max_{a}(s_{t+1},t)$ for the best state-action pair for the next state.
In vanilla Q learning, we have two Q values as well
Q(s, a) for current state-action and $max_{a}(s_{t+1},t)$ for the best state-action pair for the next state. -
Knowledge distillation
using a separate network to produce a training target for another network.While student network are being updated at every training iteration, Only update teacher/Target Network every several iterations to avoid creating a “moving target”.