RL 2024-3
Focus on PPO in this post
0 KL Divergence
KL divergence is actually related to entropy.
 It’s the loss functions for VAEs.
It’s the loss functions for VAEs.
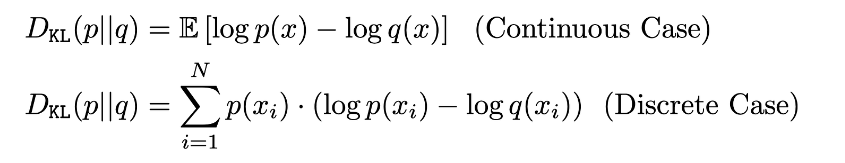
1 Trust Region Policy Optimization (TRPO)
- Use a ratio, surrogate objective, between old and updated policies
- added constraint based on the KL divergence
- Solving a contrained maximization problem instead Gradient Ascent

Comparing to VPG, instead of working on parameter $\theta$ space, directly work on policies. Because small changes to $\theta$ can drastically alter the policy, ensuring that policy updates are small in the parameter space does not provide much of a guarantee on changes to the resulting policy.
2 Proximal Policy Optimization (PPO)
Define surrogate objective for TRPO as below
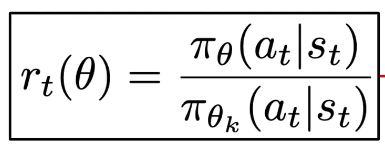 PPO’s surragte objective is a clipped version
PPO’s surragte objective is a clipped version
