RNN(LSTM) vs Mamba
Hongyee’s AI course in 2025. This one]() about Mamba really clarify the relationship between RNN and Mamba, and I finally understand the intuitive behind LSTM as well.
0 LSTM
Vanilla RNN has $f_{a/b/c}$ being constant for all steps. LSTM and GRU, these gated NN, essentially make $f_{a/b/c,t}$ depends on step $t$. A simple implementation is to generate them based on $x_t$.
$f_b$ -> Input Gate
$f_a$ -> Forgetting Gate
$f_c$ -> Output Gate
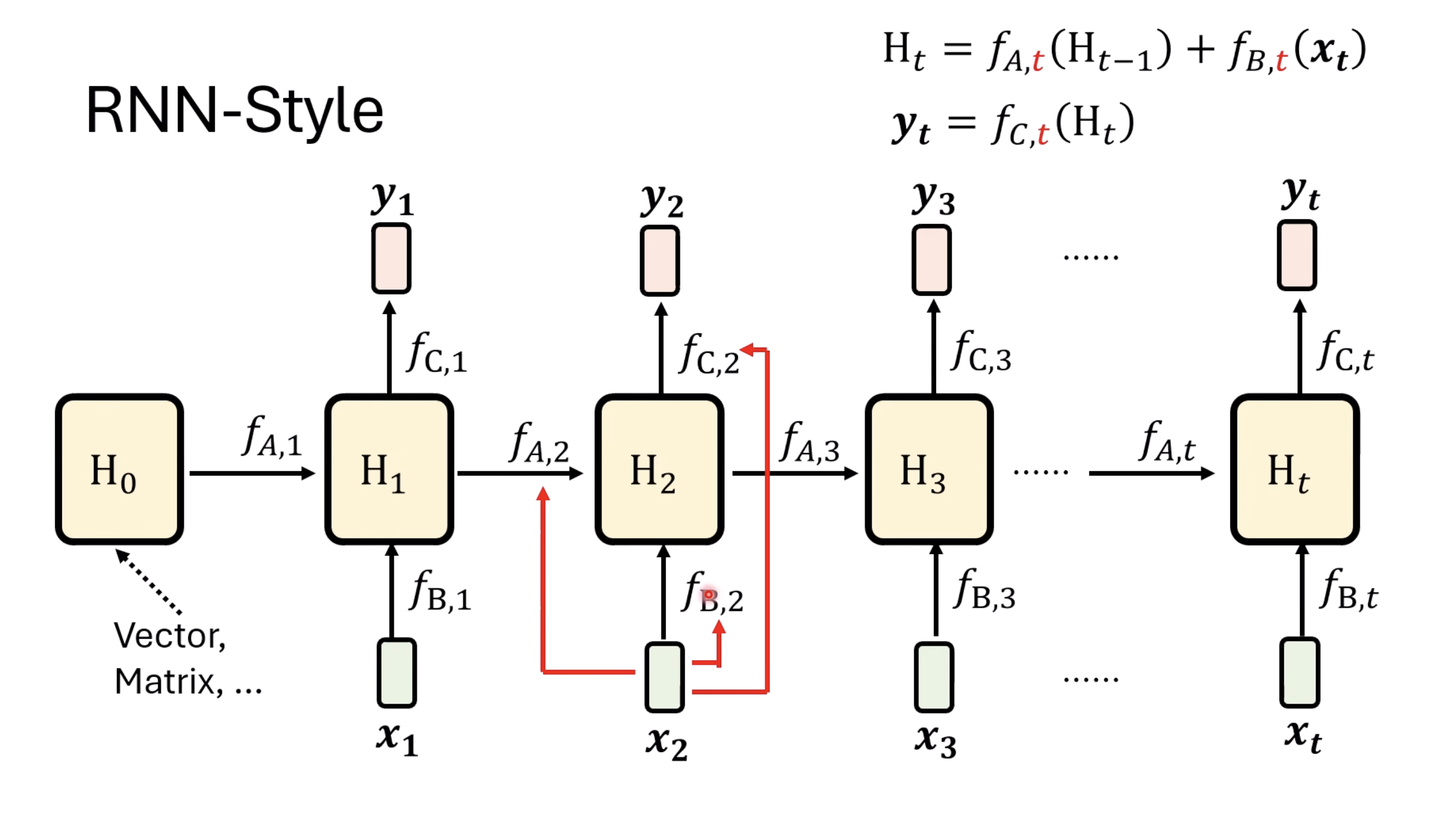
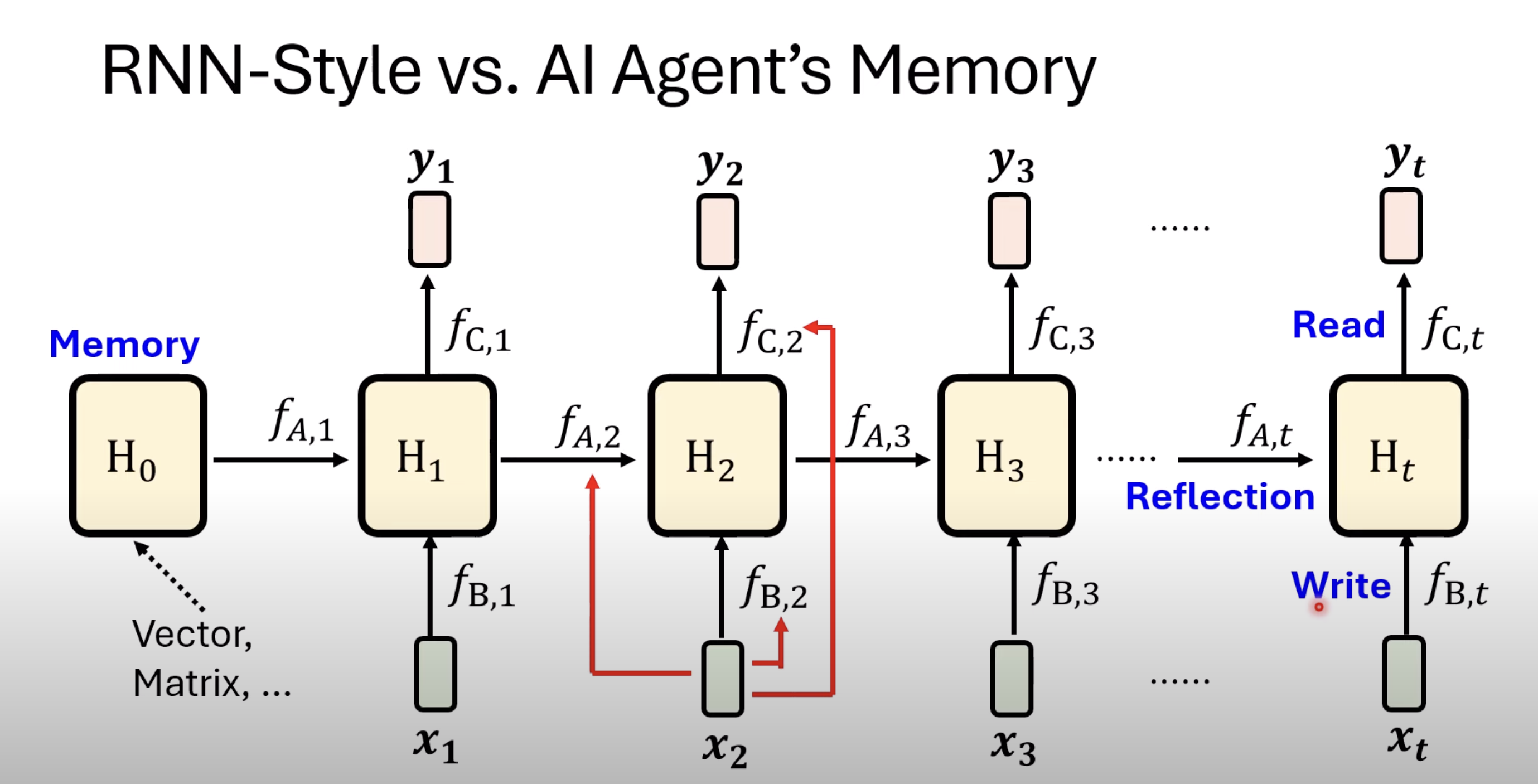
This is similar to agentic workflow as well
1 Parallelize RNN
Simply expand RNN is impossible to parallelize due to $f_a$
 If we remove $f_a$
If we remove $f_a$
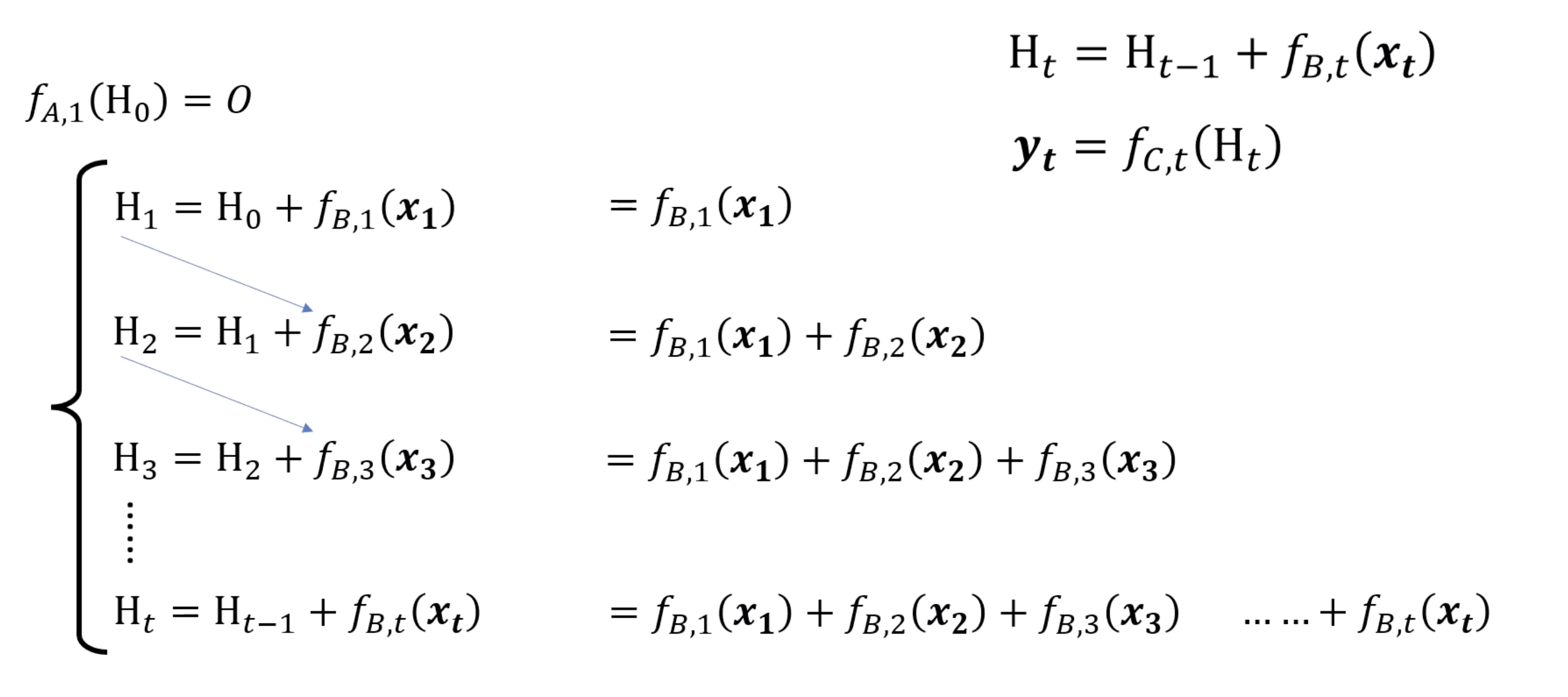 And making some simple assumption of $f_{b/c}$
And making some simple assumption of $f_{b/c}$
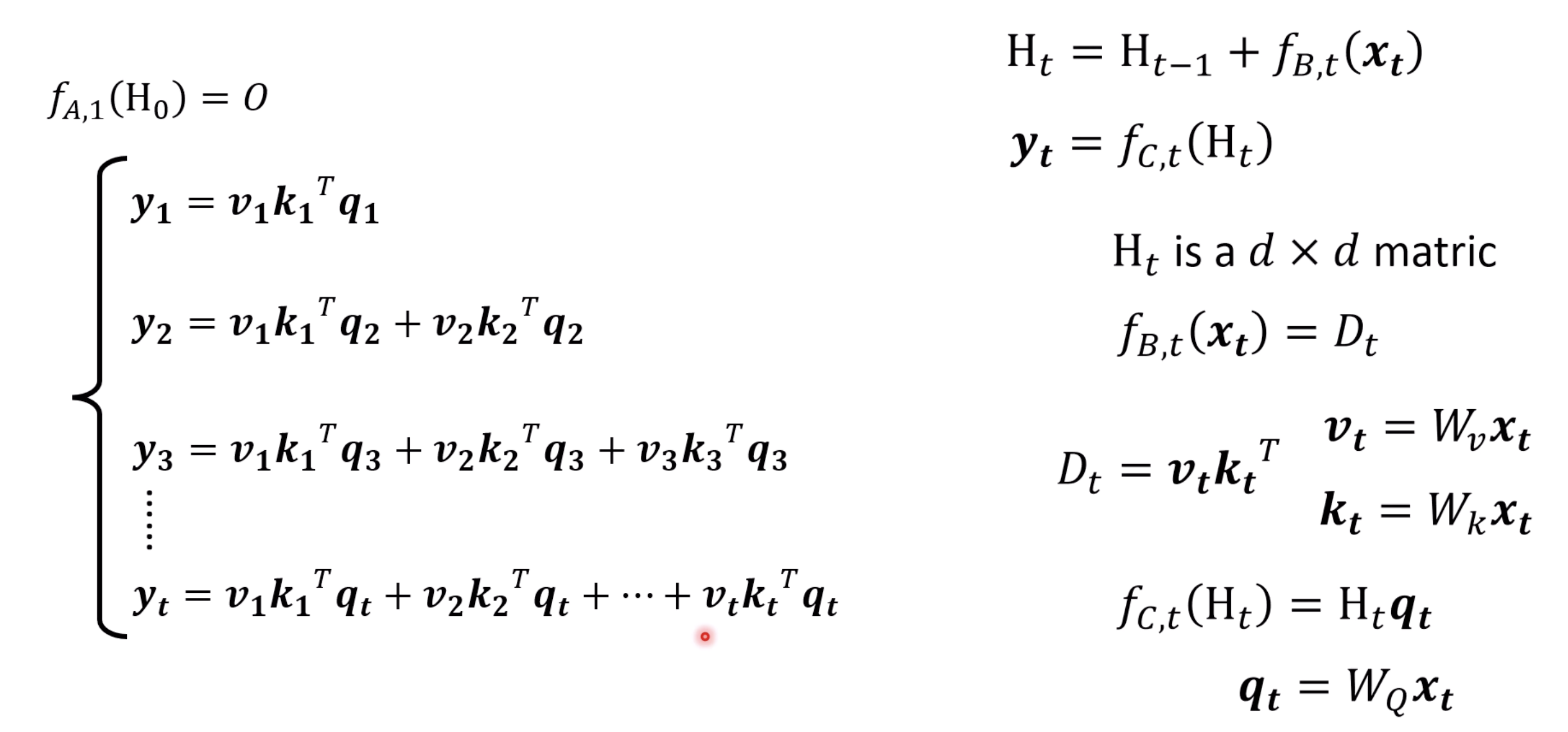 It turned out to be similar to transformers, excepts for softmax. This is called linear transformers
It turned out to be similar to transformers, excepts for softmax. This is called linear transformers

Here is another view of Q/K/V matrix
K decides which column of V write into memory block
 Q decides which column retrieves from memory block.
Q decides which column retrieves from memory block.

2 RNN/Linear Transformaers vs Transformers
Is RNN memory really limited? Obviously it is and it’s bounded by the size of $H_t$, but we still can modify H size
 The interesting part is that transformer memory is NOT unlimited. The dimention/rank of $W$ also limited the information it can take
The interesting part is that transformer memory is NOT unlimited. The dimention/rank of $W$ also limited the information it can take
 So what makes transformer working is really the softmax layer!
So what makes transformer working is really the softmax layer!
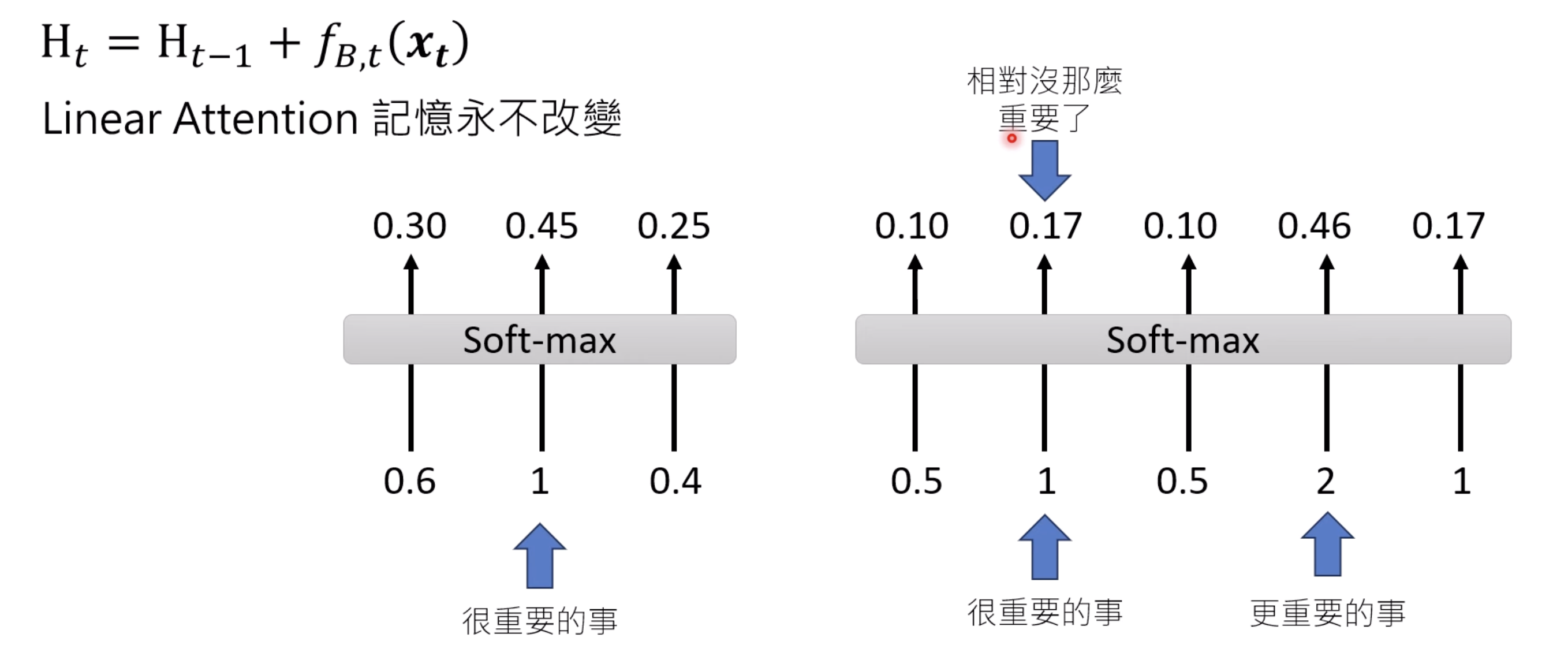
3 Variants of Gated RNN
Softmax is making transformers to “forget” some previous saved information. And we can apply a factor to achieve similar effect.

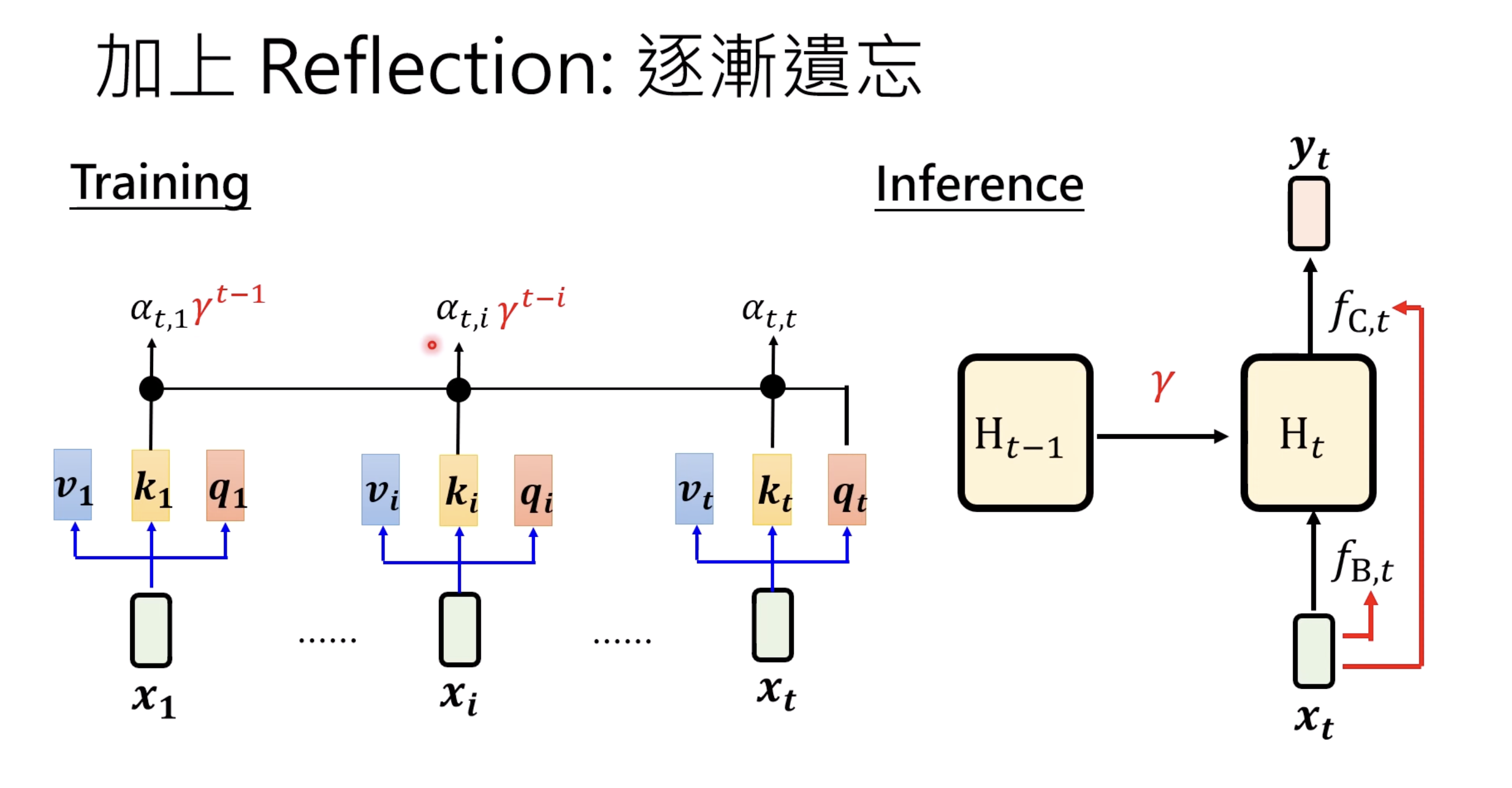 The Gated version is making $\gamma$ time dependent
The Gated version is making $\gamma$ time dependent
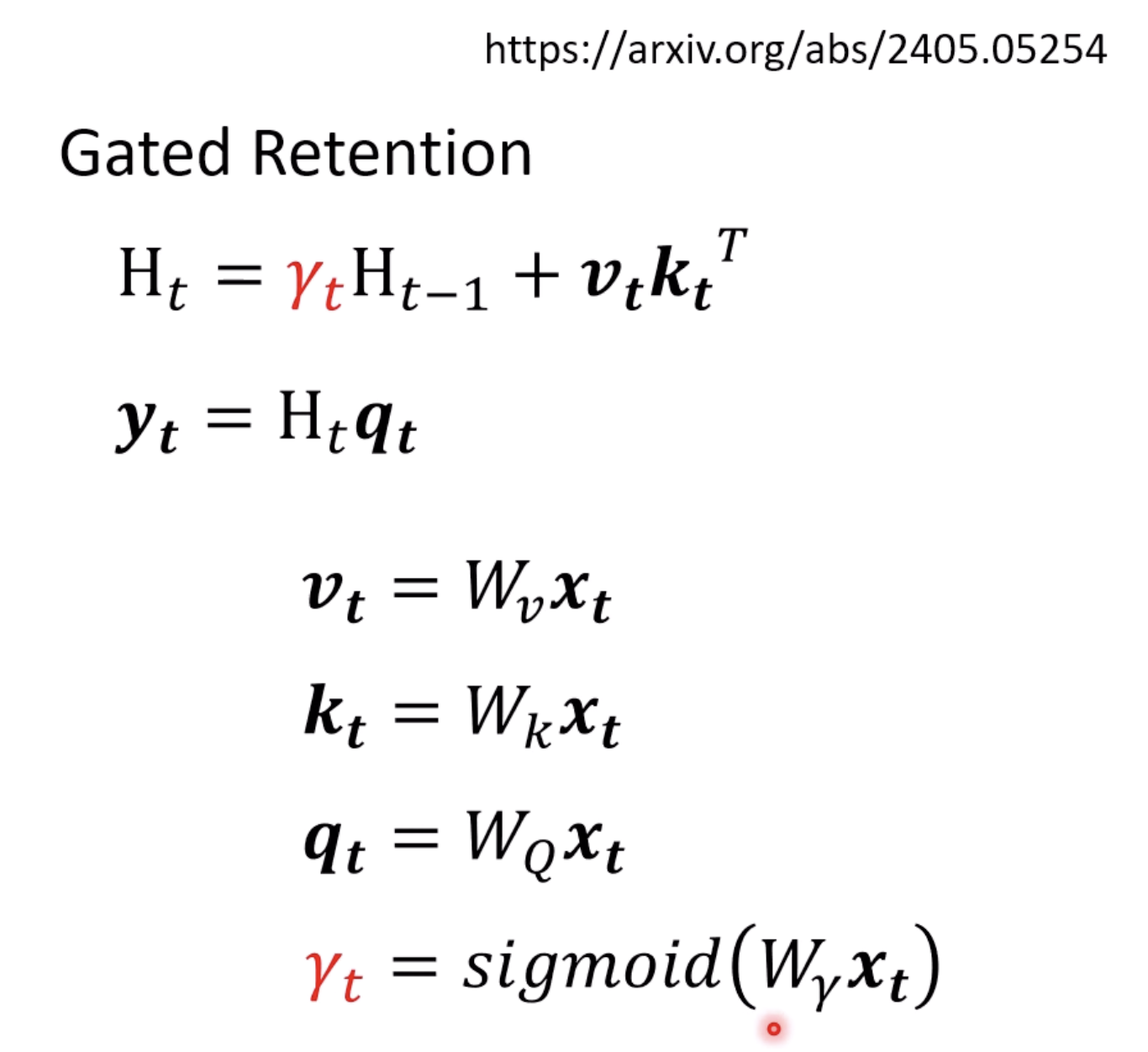
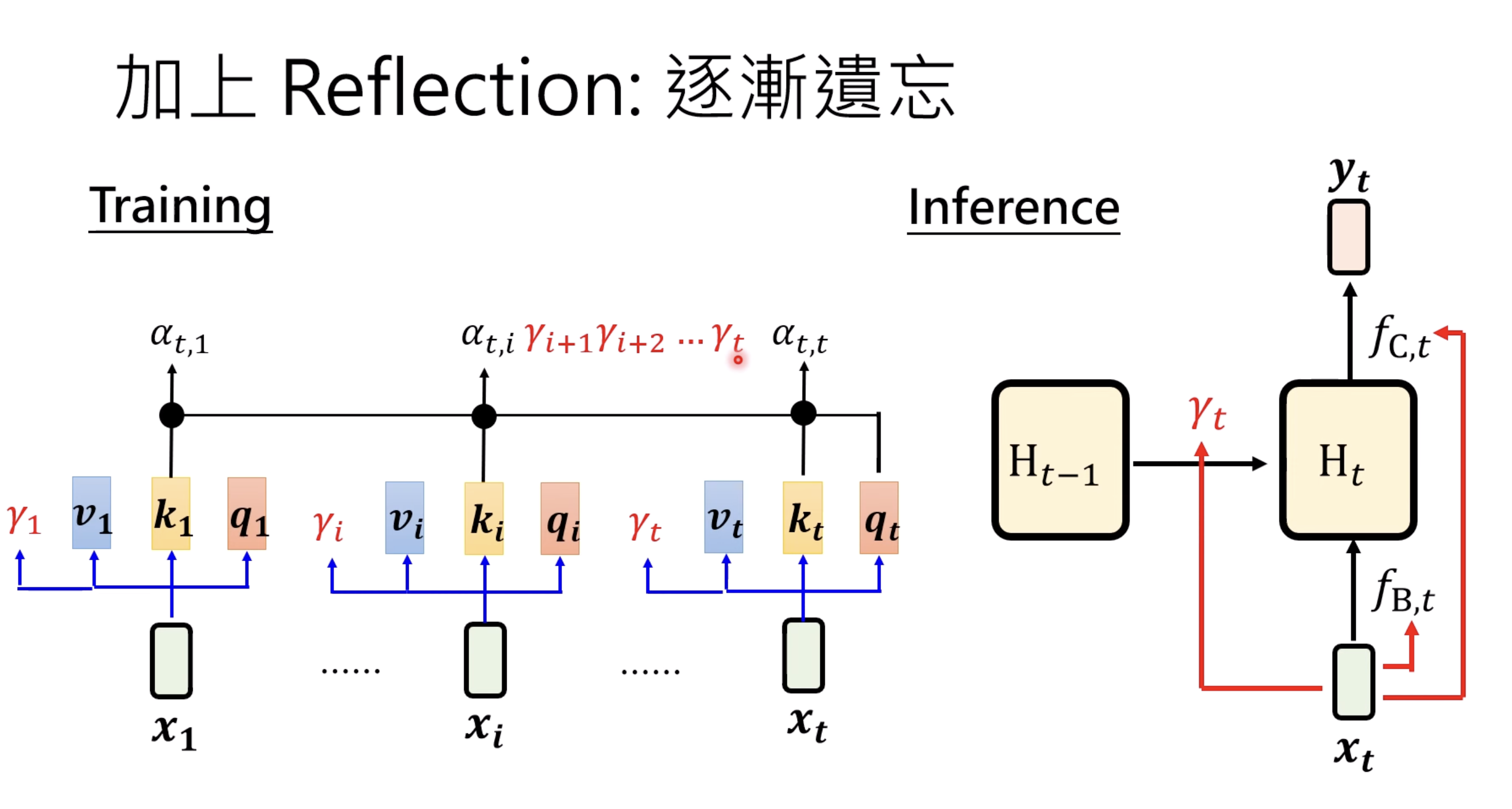
Here is an element-wise modification of the memory
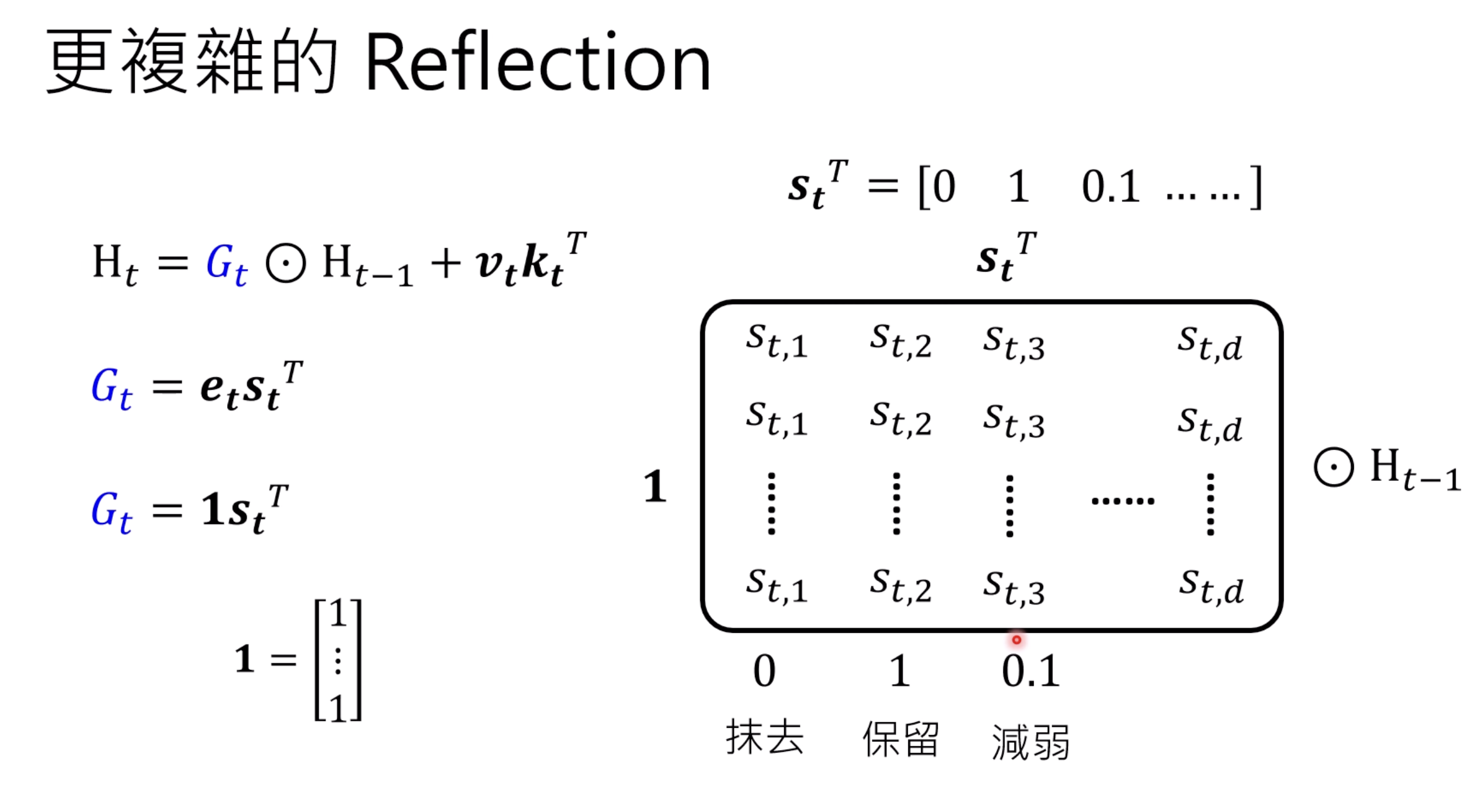 Mamba and Mamba 2 are another variants.
Mamba and Mamba 2 are another variants.

4 DeltaNet and Mamba applications
The DeltaNet is another variant, and it removed the old value selected and add back a new value. $\beta$ is used to control the ratio. The interesting part is that it ends up as GD method.

Jamba - Mamba from AI21, 52B
MiniMax - Linear attention w 400B
Sana - Linear attention in visual
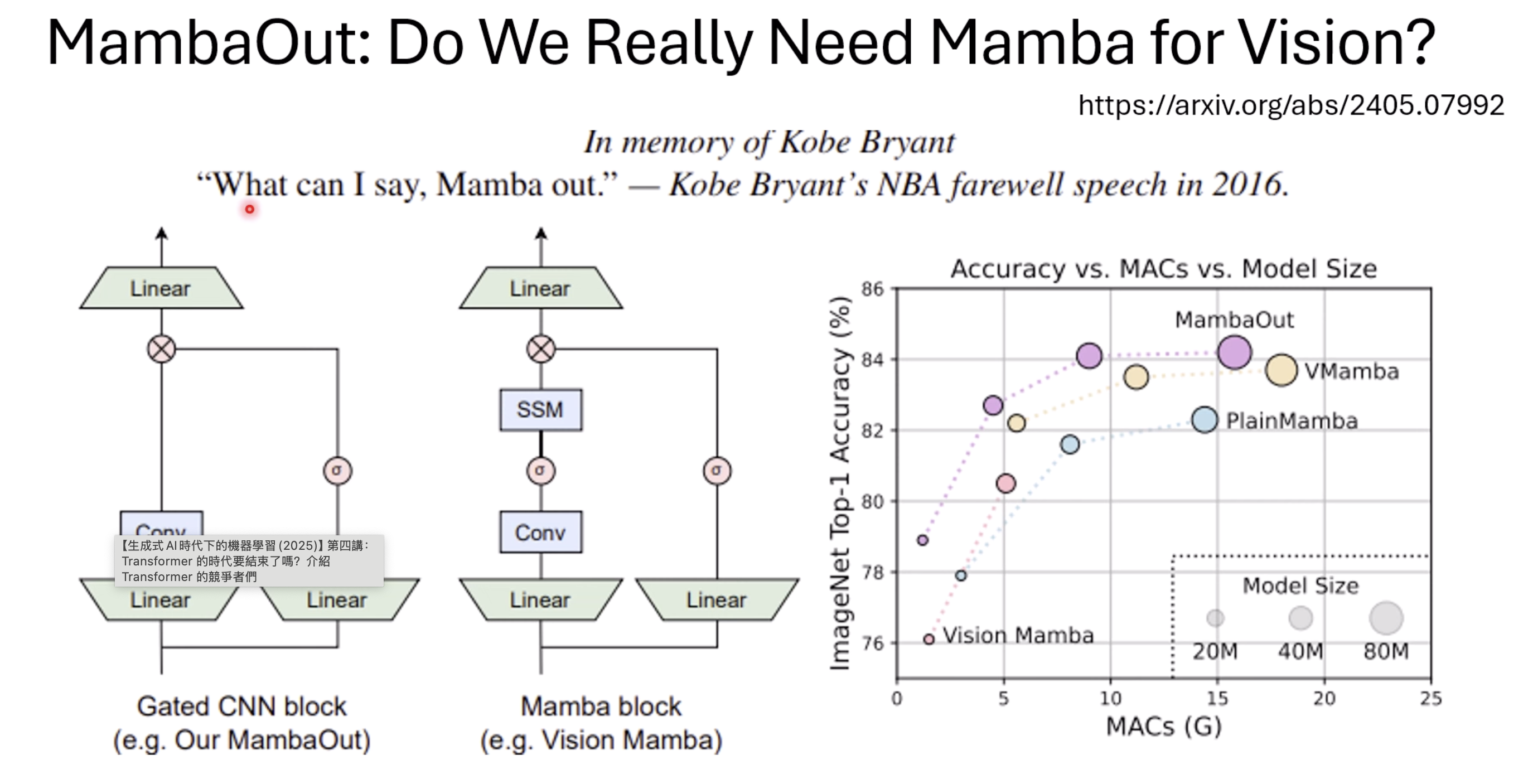
Do we really need Mamba in visual task?
It may NOT needed in classification.
An intereting bet, https://www.isattentionallyouneed.com/ ???