SGLang
How does Structured Generation Language for LLM achieve such great performances and how is it differentiate from vLLM.
Lianmin presented SGLang here explains key 4 technicals
0 History
SGLang history and milestones.

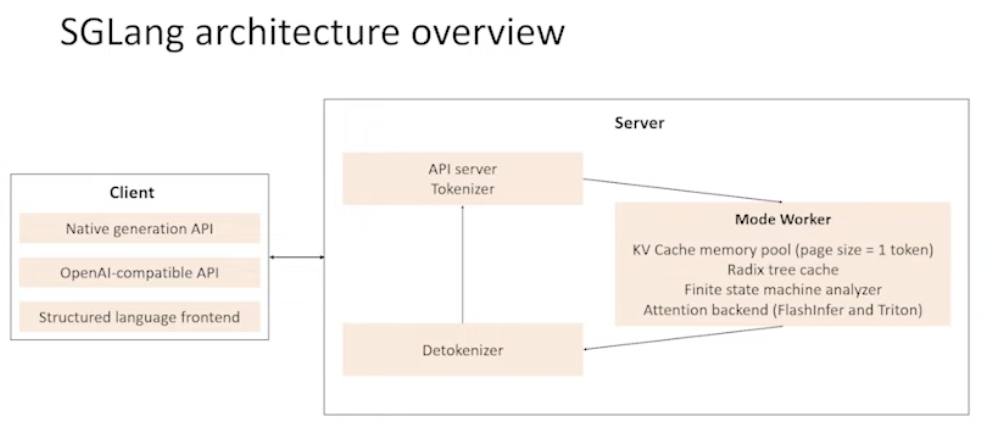
 Key architecture is here, and will focus on server side
Key architecture is here, and will focus on server side
Highly recommend this blog talks about the positioning of SGLang. If vLLM is Caffe, SGLang is maybe Tensorflow? What will be the Pytorch of LLM infer framework ?
1 LM Programes
SGLang was designed to solve LM program constrains:
- Multiple LLM calls
- Need constrained decoding.

It has its own language primitives. It’s similar to LMQL and Guidance

Here is a full example using SGLang and it includes 3 key improvments (The 3rd one is for API calls only)

2 RadixAttention
KV cache is highly repeatable
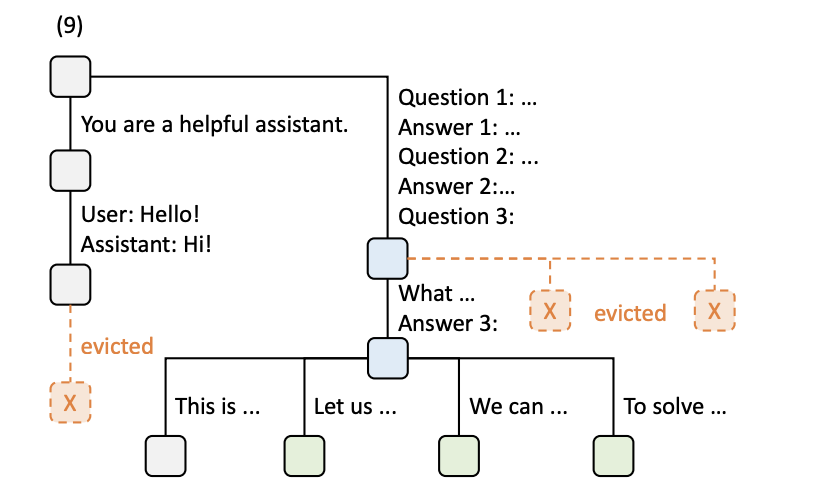
 The Radix Tree is a compressed prefix tree, and it’s used to store KV cache for reuse.
The Radix Tree is a compressed prefix tree, and it’s used to store KV cache for reuse.
3 Compressed FSM
FSM from Outlines is one common used method to force JSON schema. The limitation is only decode one token at a time.
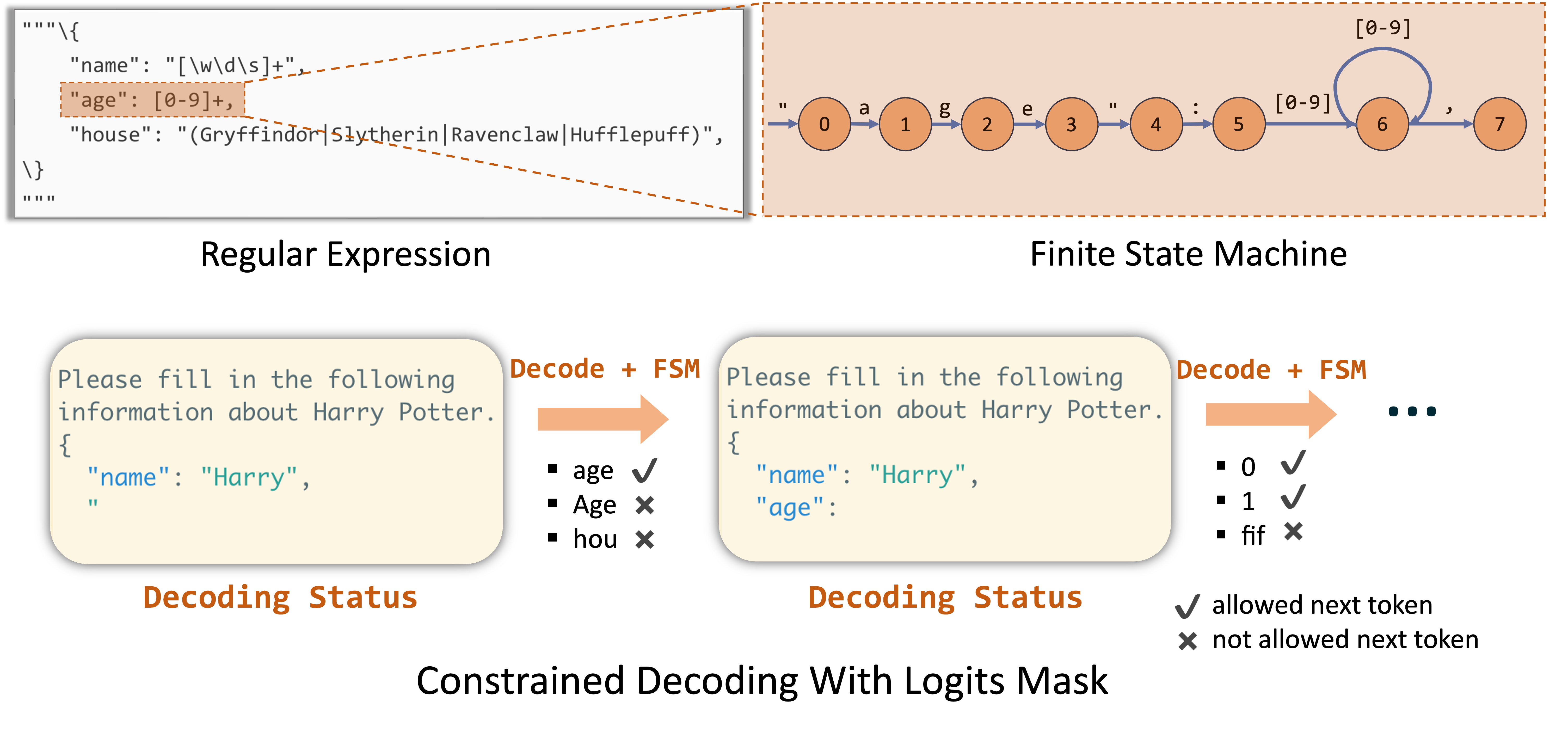 An improvement is from Guidance to employ interleaved-based decoding. A JSON schema can be breakdown into either a chunked prefill part or a constrained decoding part. The former can generate multiple tokens at one tim.
More details in this blog
An improvement is from Guidance to employ interleaved-based decoding. A JSON schema can be breakdown into either a chunked prefill part or a constrained decoding part. The former can generate multiple tokens at one tim.
More details in this blog

Jump-Foward Decoding is a compressed FSM combining these two methods by compressing singular transition edges.
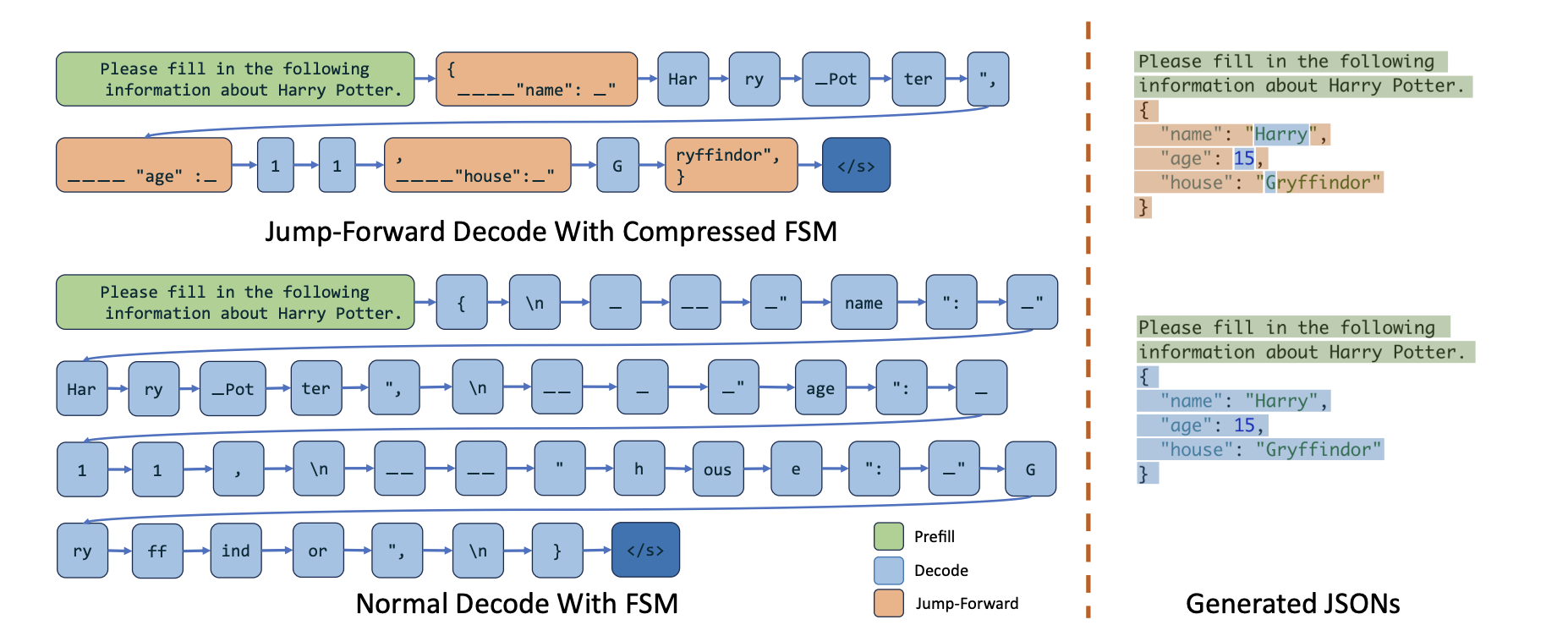
4 Speculative API calls
This is a trival trick of ignoring ending tokens and it make API output more contents for possible future use by prompting.
Pytorch compile is also one thing mentioned by Lianmin. and the following 3 optimization are not included in the orignal paper, and details are found in this video by Yineng Zhang.
5 CPU Overlap Optimization
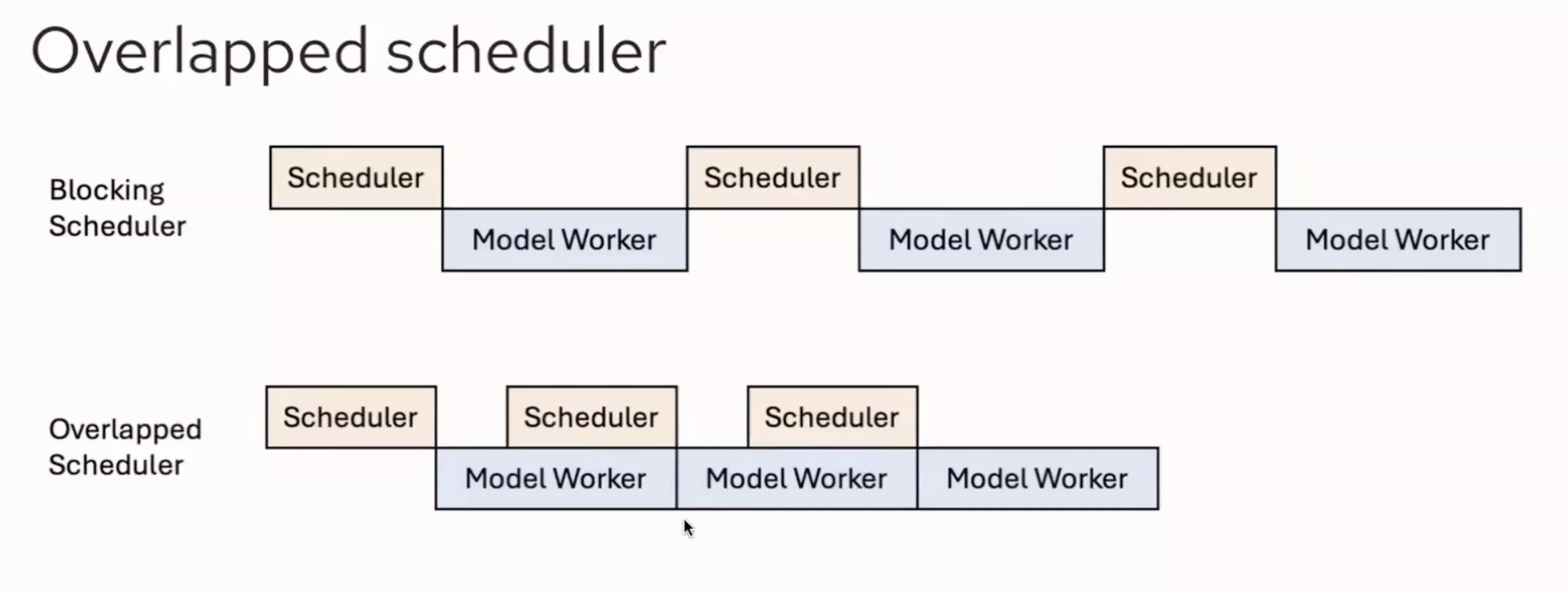
6 FlashInfer Hopper Optimization and Integration
FlashInfer gives better perf than Triton implementation.
 Key improvements from it are
Key improvements from it are
 StreamK are SM level optimizations.
StreamK are SM level optimizations.

7 TurboMind GEMM Optimization and Integration
 LDSM is the CUDA code for “Load Matrix from Shared Memory with Element Size Expansion”
LDSM is the CUDA code for “Load Matrix from Shared Memory with Element Size Expansion”
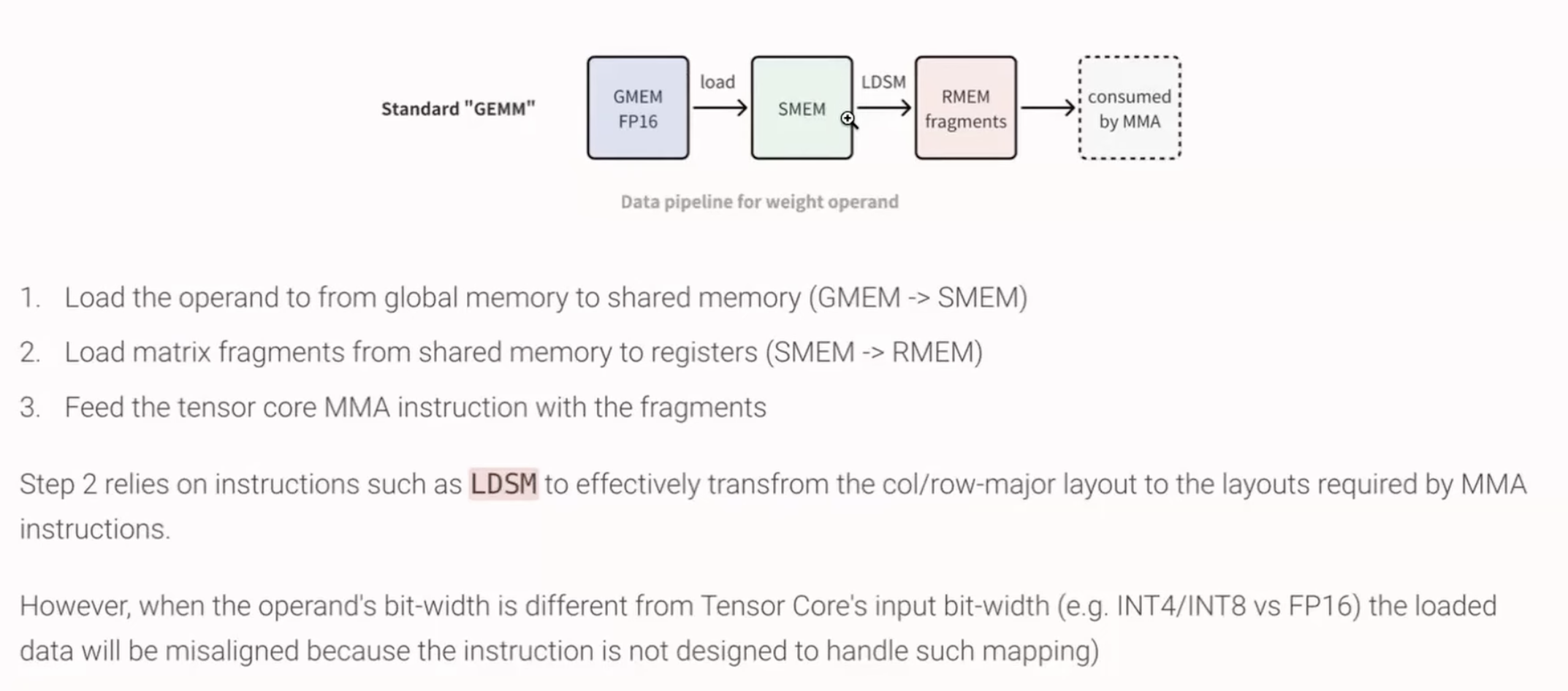 Improvement on GEMM(GEneral Matrix to Matrix) is totally out of my knowledge
Improvement on GEMM(GEneral Matrix to Matrix) is totally out of my knowledge