Structured Output
How can LLM follow the format defined in structured output?
One good explanation is this youtube video and blog from vLLM
0 A brief historical context
GOFAI(Good-Old-Fashioned AI) are deterministic and rule-based, given its intentionality is injected through explicit programming NFAI(New Fangled AI) are often considered as “black-box” models, data-driven given the networked complexity nature of its internal representations
1 OpenAI API and Outlines lib
OAI uses Pydantic and Outlier use Regex expression.
A finte state machine was maintained for regular express output. You track at which state the tokens are in, and check if the following tokens are valid or not.

The performance of this method is hard to scale in real case. The solution is pre-generate all possibile tokens from this step
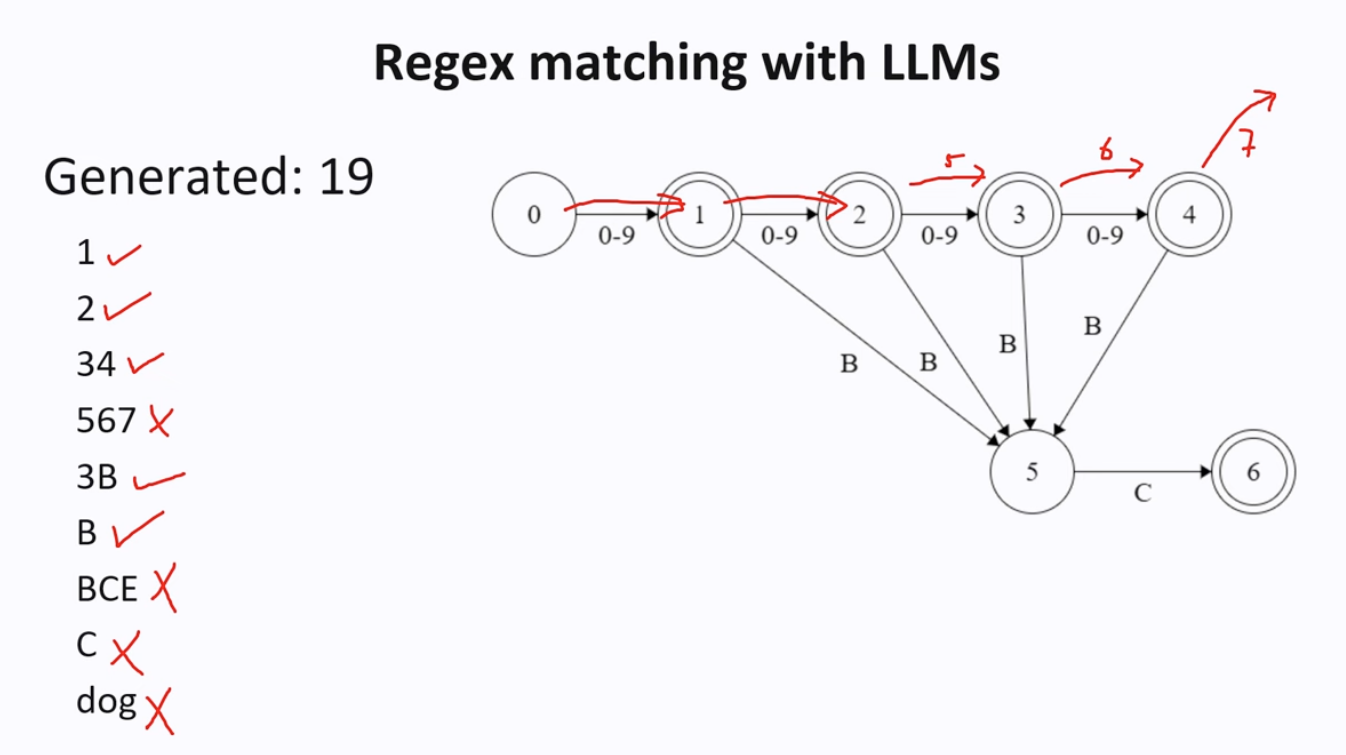
2 Context-Free Grammar
CFG(Context Free Grammar) allows multiple levels of nesting. Structured JSON with limited nesting can be solved by Regex but deeply nested structured text would need CFG.
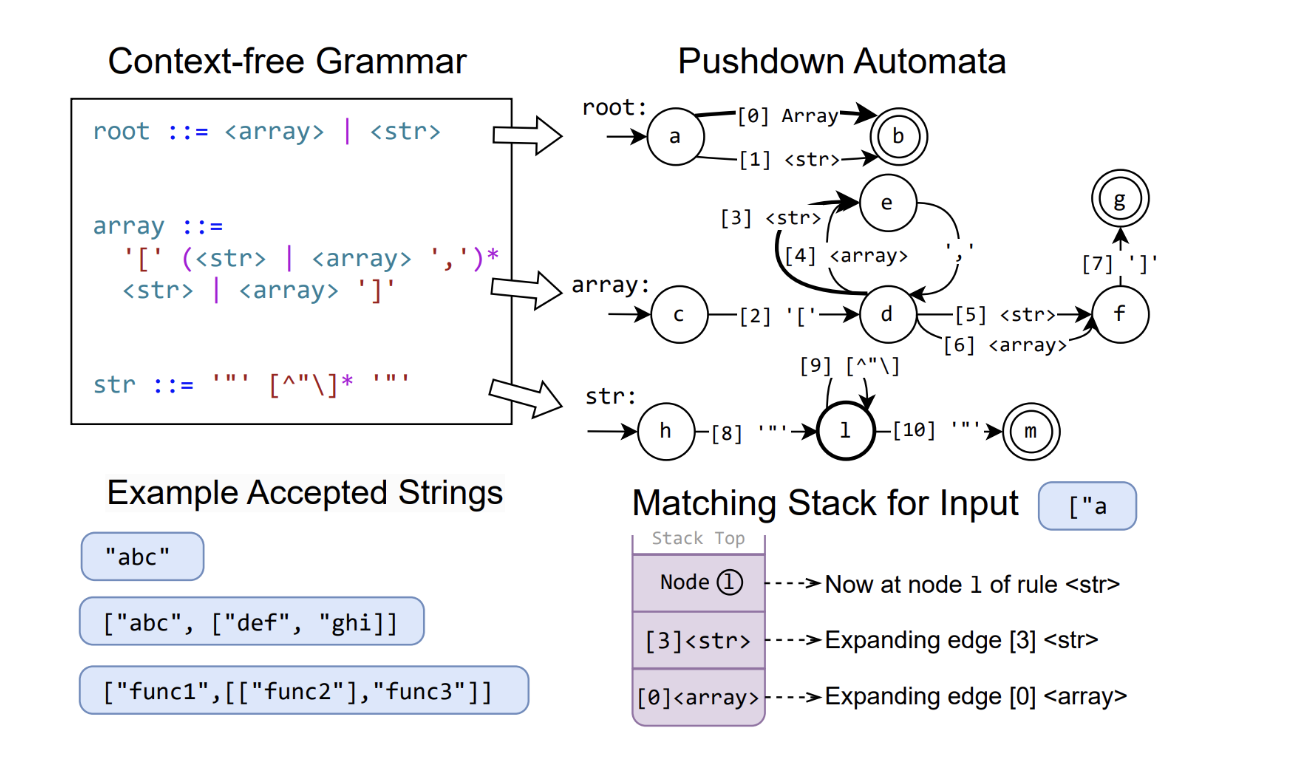
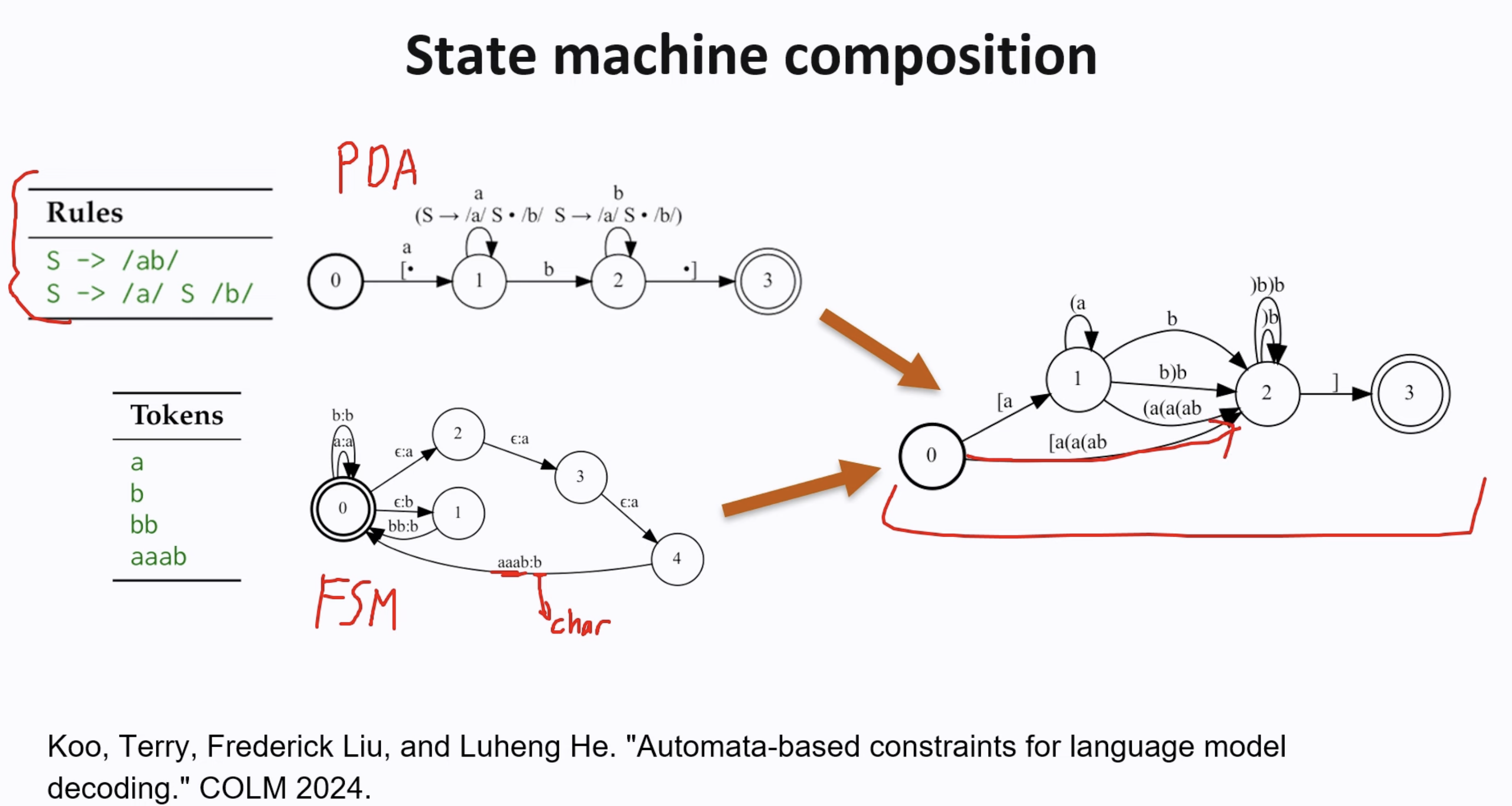
3 Pushdown Automata
PDA is a common approach to execute a CFG, which is a combination of FSM and a stack. There is a whole new field for me to understand automata, and I will skip the details…
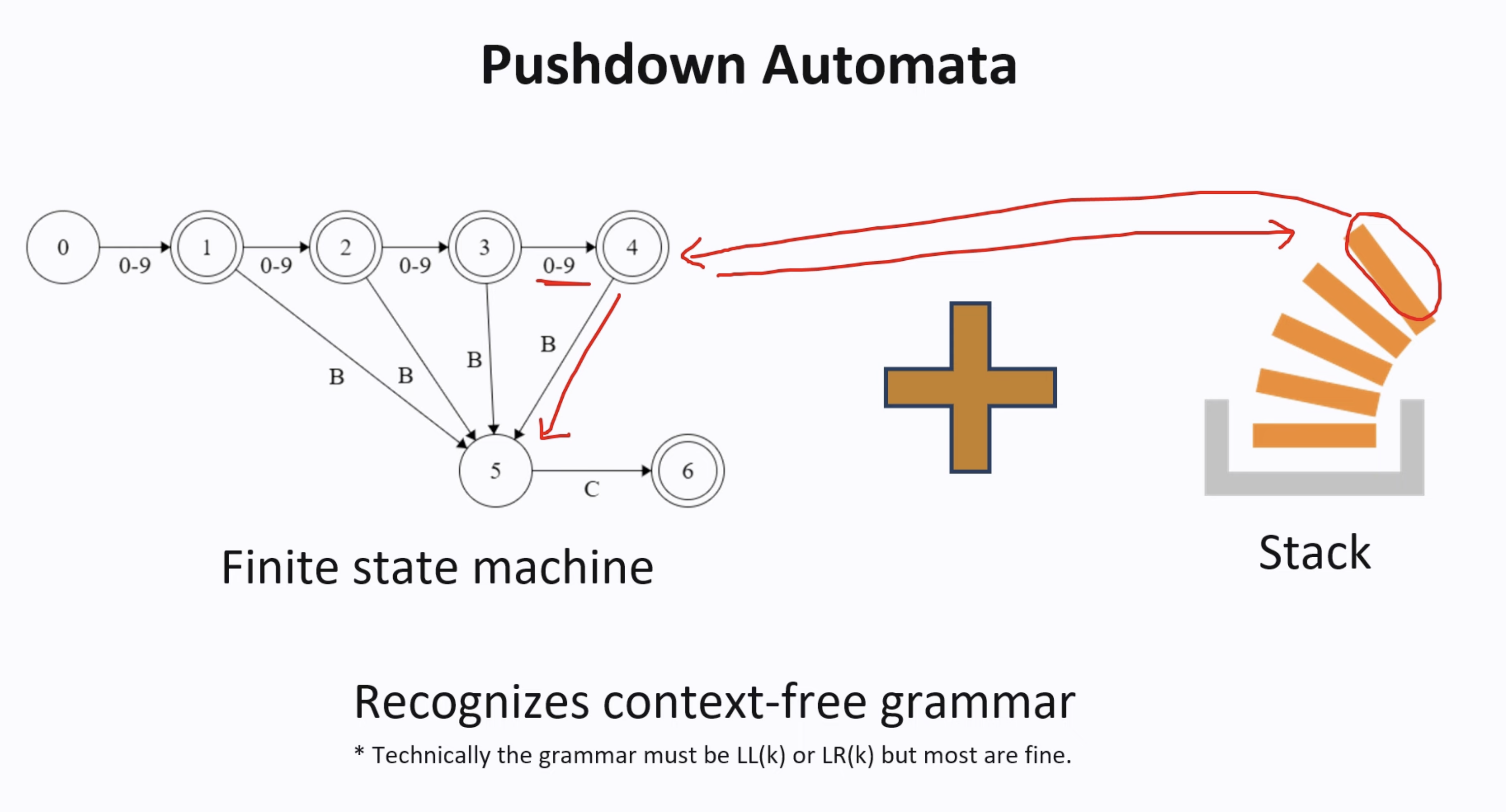
XGrammar is an implementation of PDA and achieve great performance. You can think of a PDA as a collection of FSMs, and each FSM represents a context-free grammar (CFG)
There is token-terminal mismatch problem due to tokenization of LLM, and it would mess up the nesting matches.
4 Latest studies
One research about subgrammar
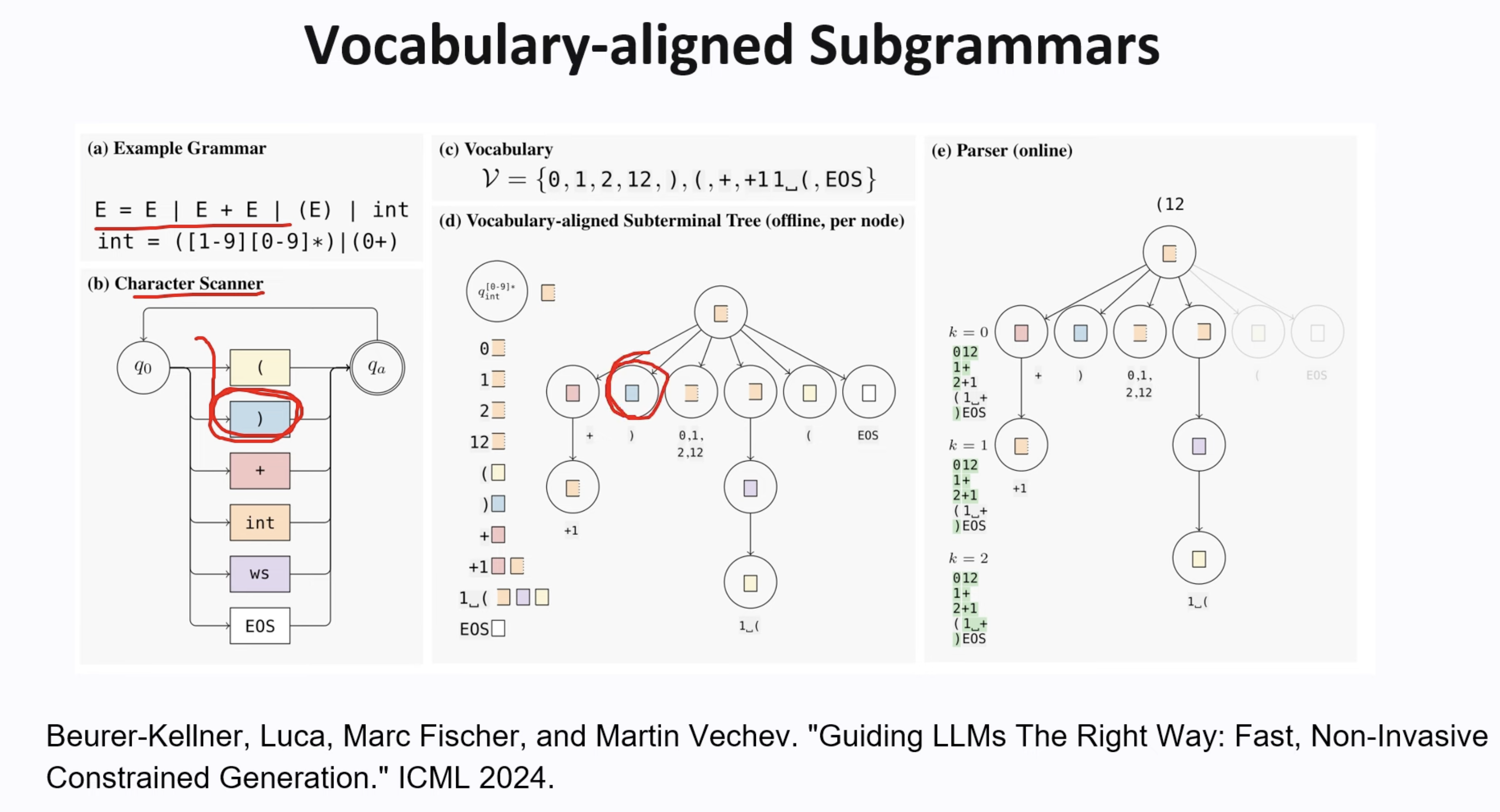 A paper from Deepmind combined PDA(Pushdown Automata) and FSM.
A paper from Deepmind combined PDA(Pushdown Automata) and FSM.
5 Performance
Structured output may hurt performance
