Tensor Parallelism and Pipeline Parallelism
There are multiple parallelism strategies from video
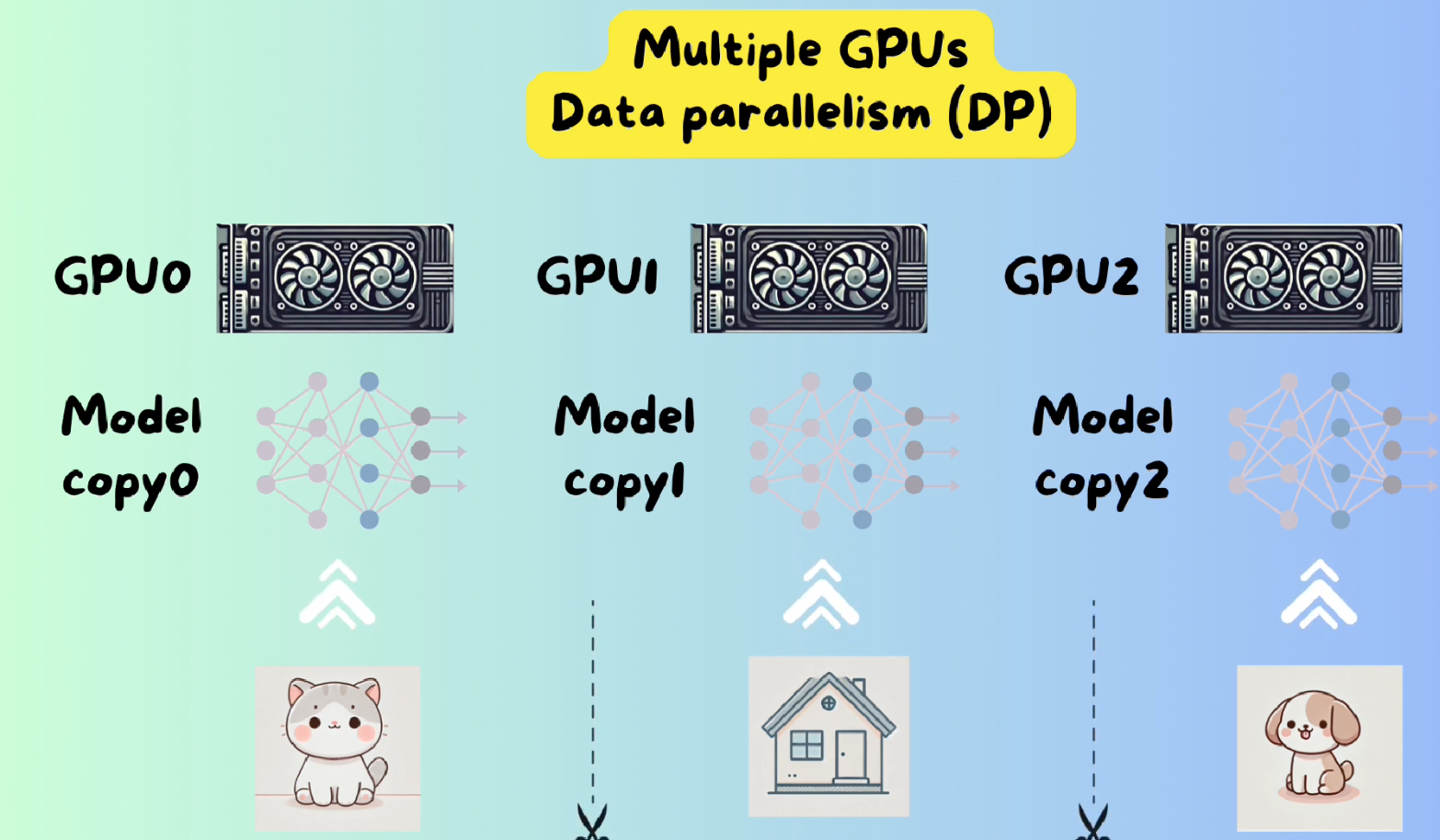
1 Data Parallelism
This basic parallelism is split data between GPUs
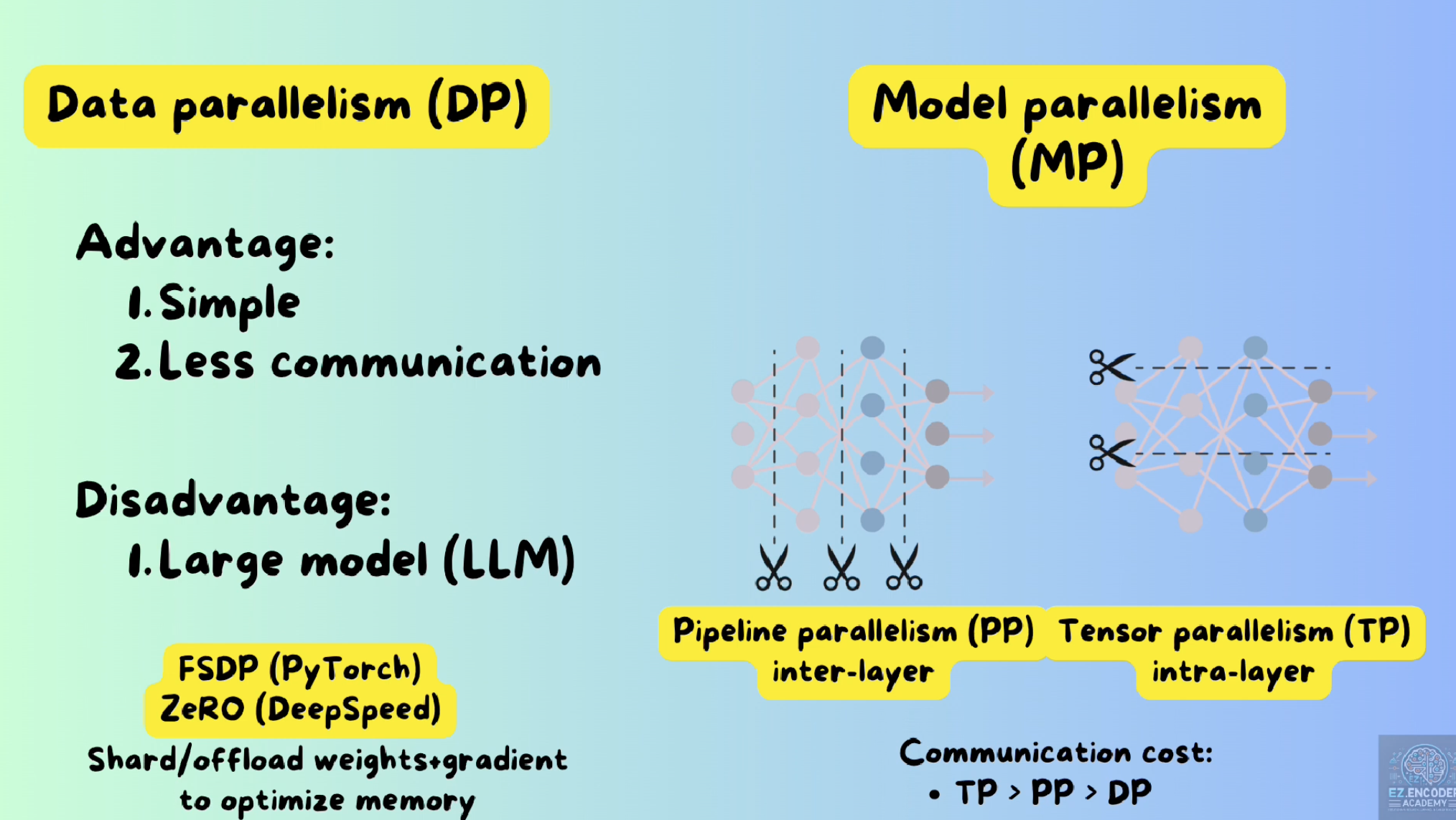
 In the LLM era, model parallelism are actually used
In the LLM era, model parallelism are actually used
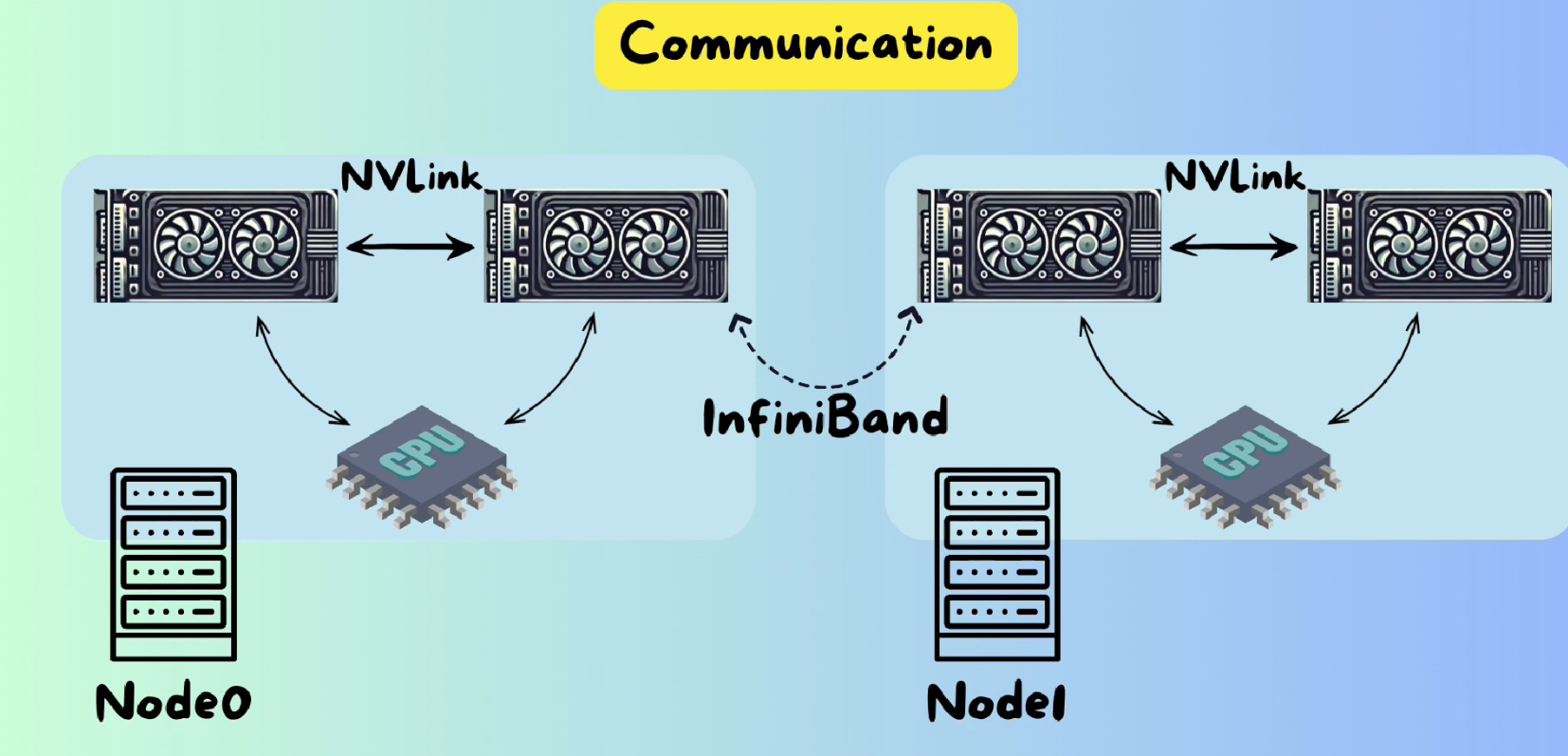
 Callout NVLink between GPUs and InfiniBand between nodes.
SXM version GPU are GPU with NVLink connections, instead of PCIe
Callout NVLink between GPUs and InfiniBand between nodes.
SXM version GPU are GPU with NVLink connections, instead of PCIe
2 Pipeline Parallelism
Also call inter-layer parallelism. (inter- means between)
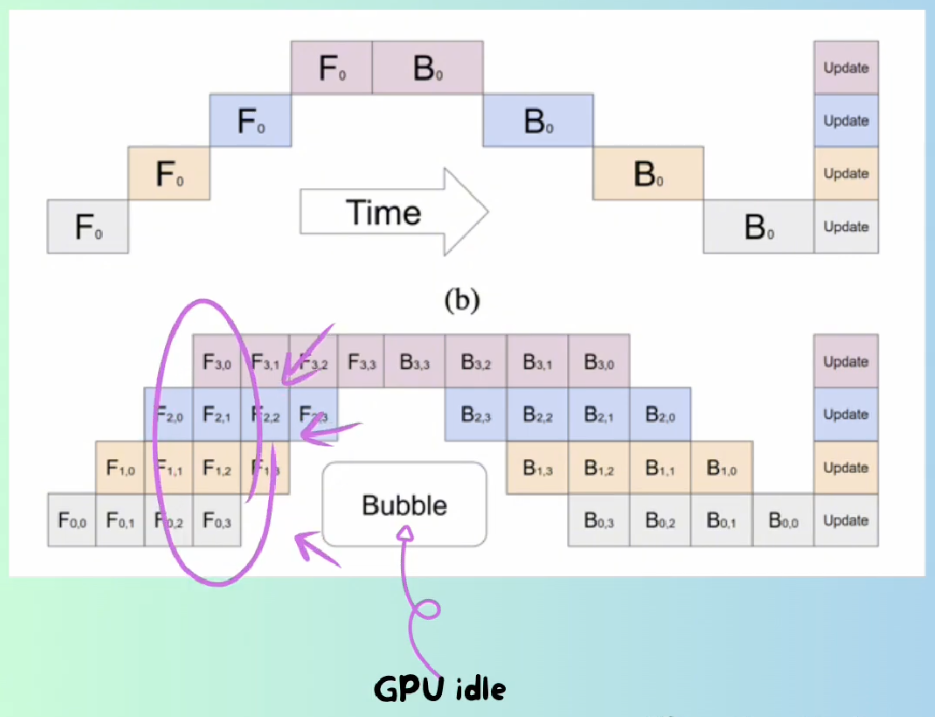
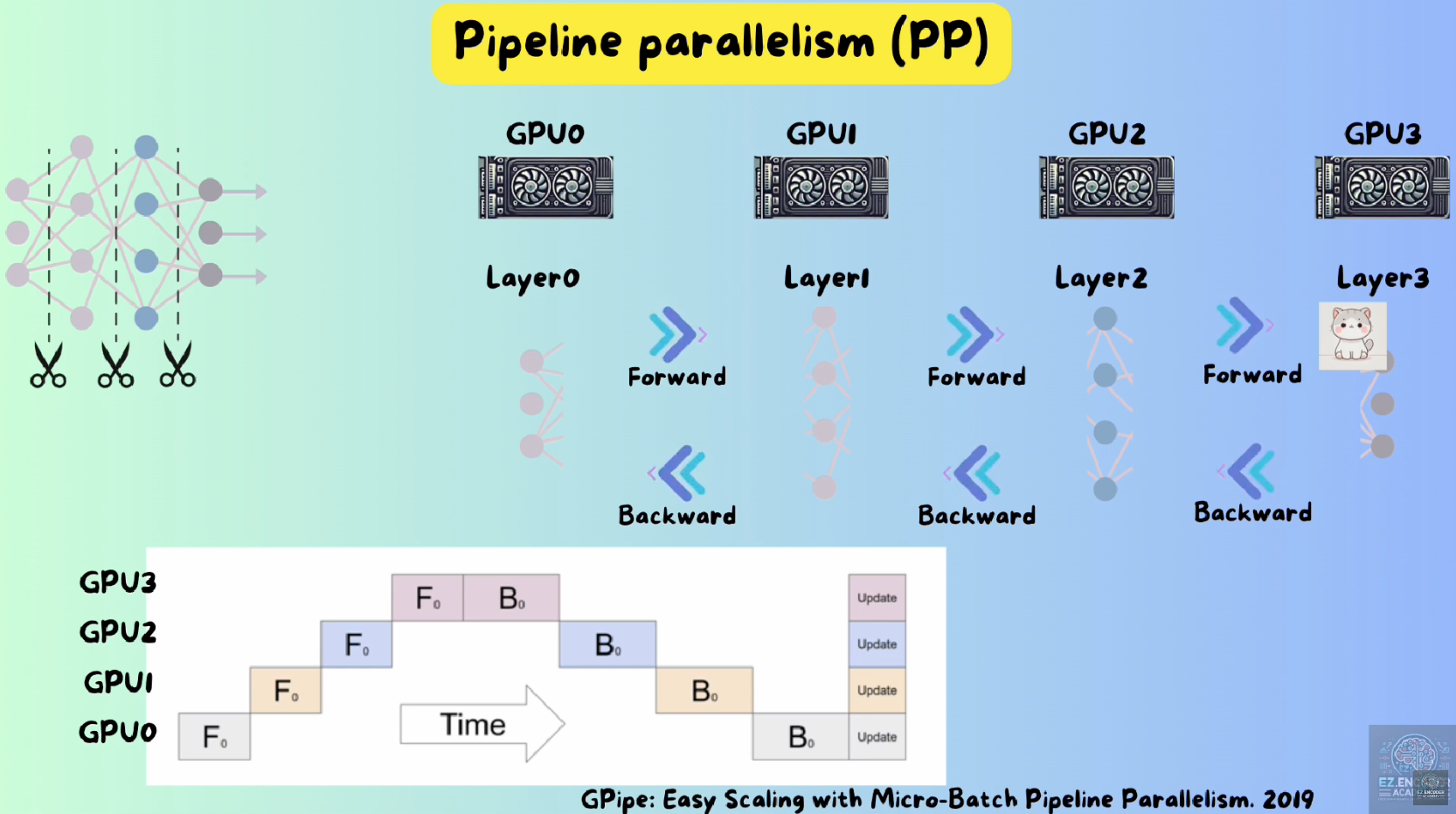 It has bubbles so Google paper introduced micro-batch to mitigate the time waste.
It has bubbles so Google paper introduced micro-batch to mitigate the time waste.
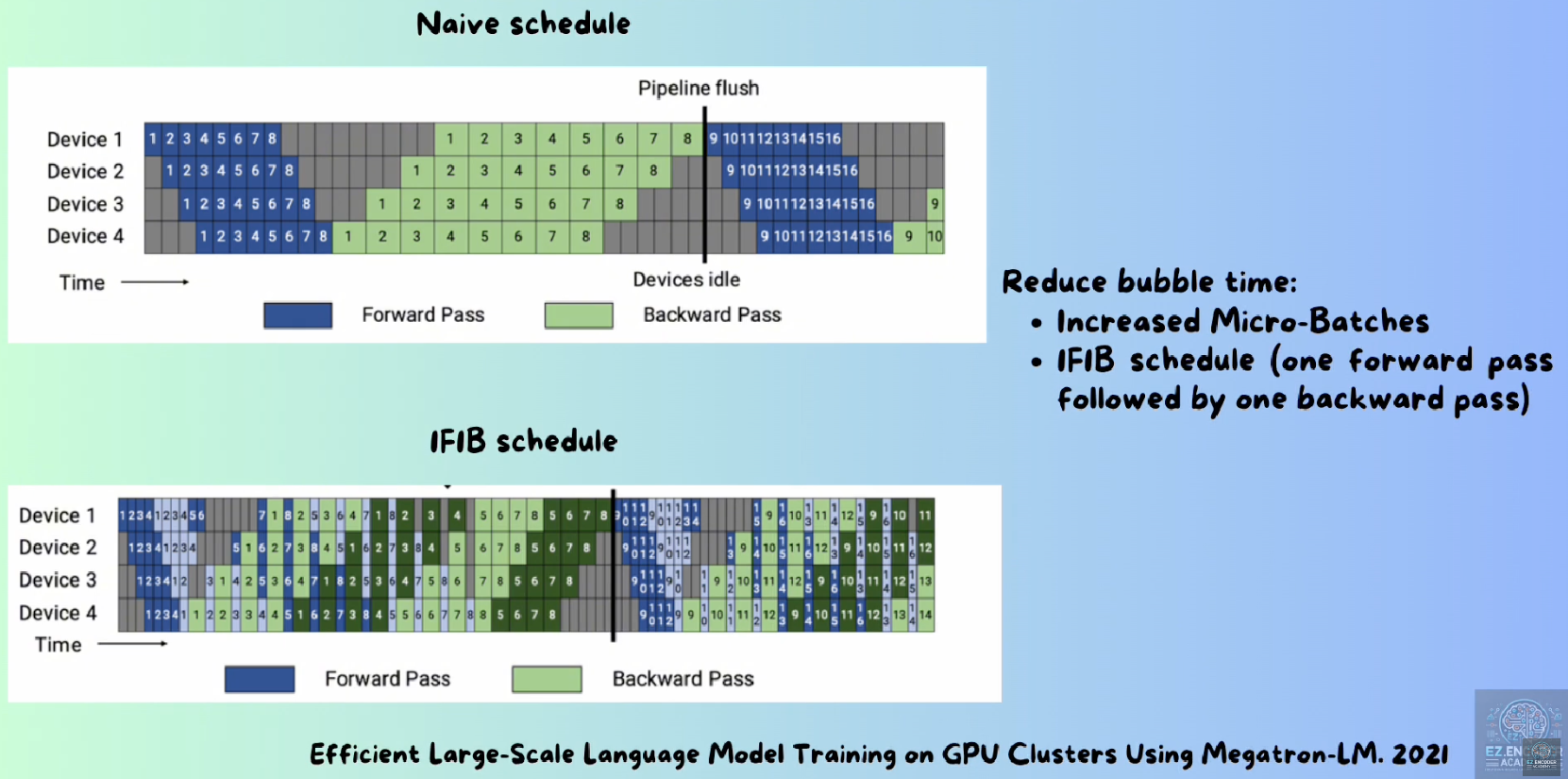
 NVidia introduced 1F1B in this blog
NVidia introduced 1F1B in this blog
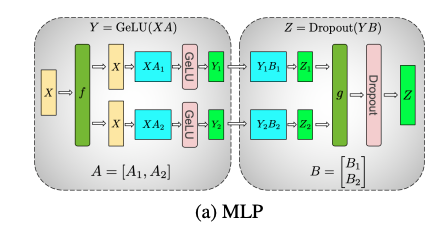
3 Tensor Parallelism
Also call intra-layer parallelism. (intra- means within)
Matrix calculation can be divided, so it leads to TP algorithm
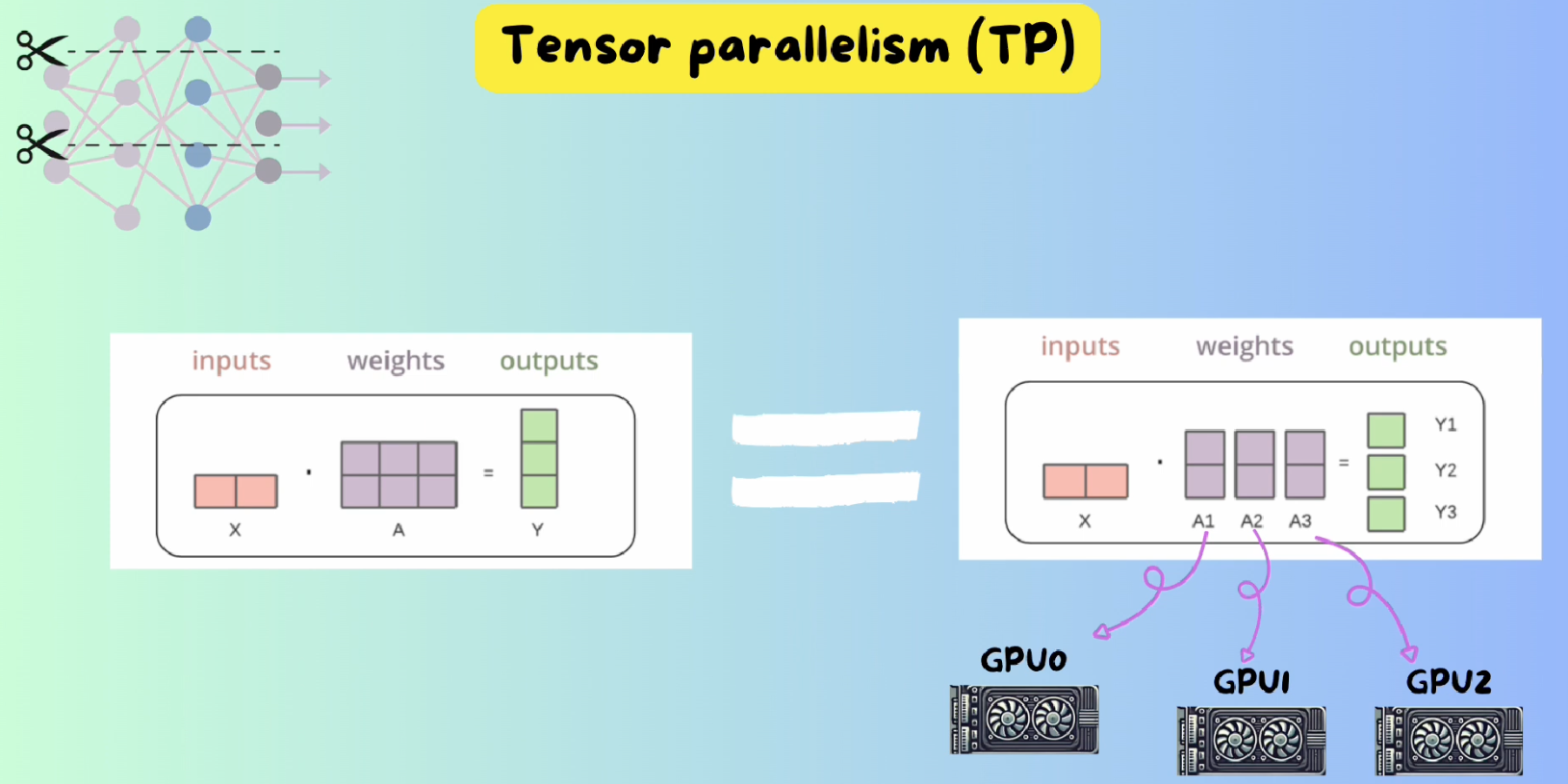
Examples can be found in the Megatron-LM paper
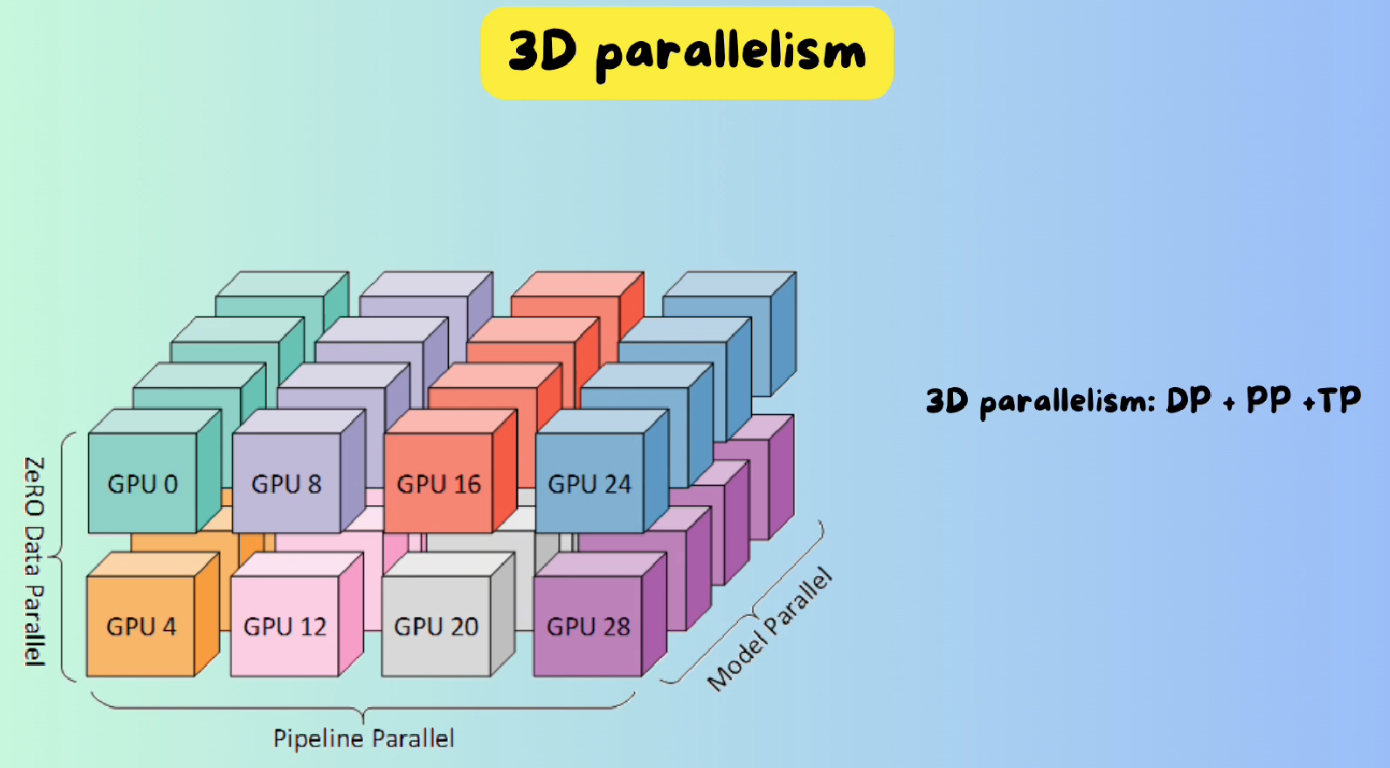
4 3D Parallelism
All these method can be used together and that’s the idea behind Deepspeed.