Image Text Fusion
Jump into Multi Models before June. This video talks 6 different ways to fuse text and image together.
Before the summary of 6 methods, two paper were called out for examples
-
ViLT Visual and Language Transformer shows the role of text embedding, visual embedding and modality integration. There three parts are the basis of multi modal models
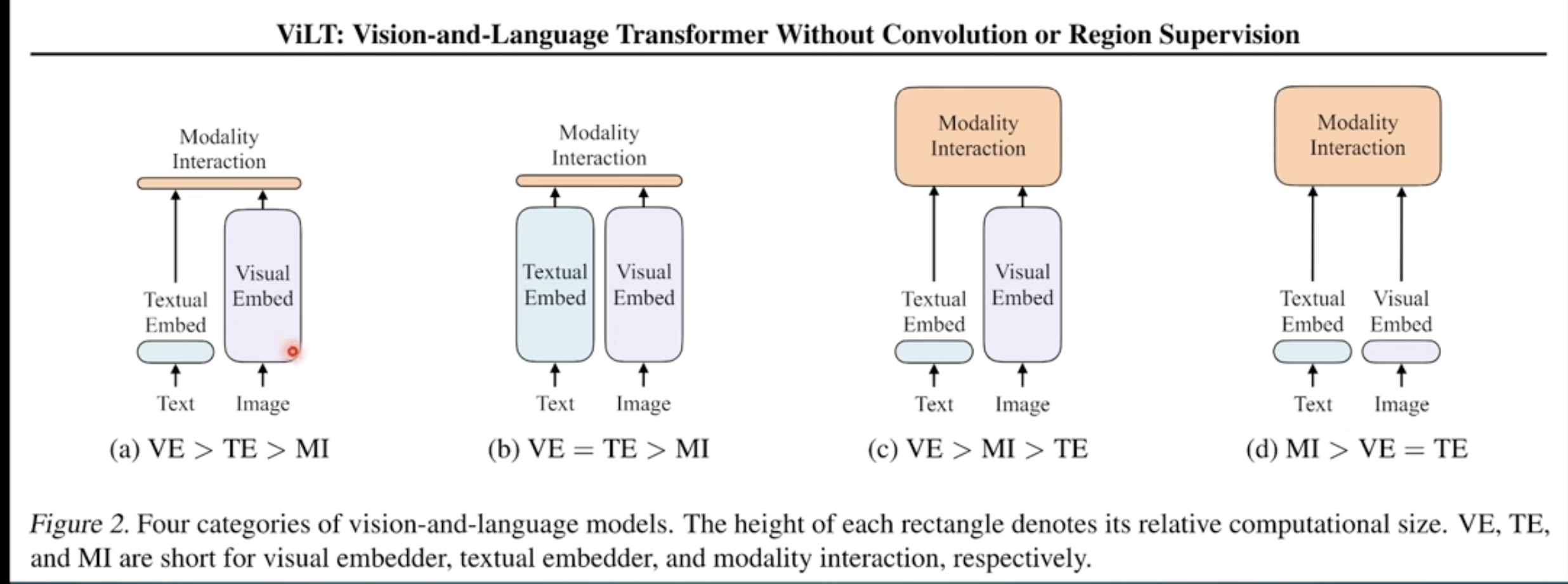 The implementation in ViLT is as follow, just concatentate VE an TE into transformers
The implementation in ViLT is as follow, just concatentate VE an TE into transformers
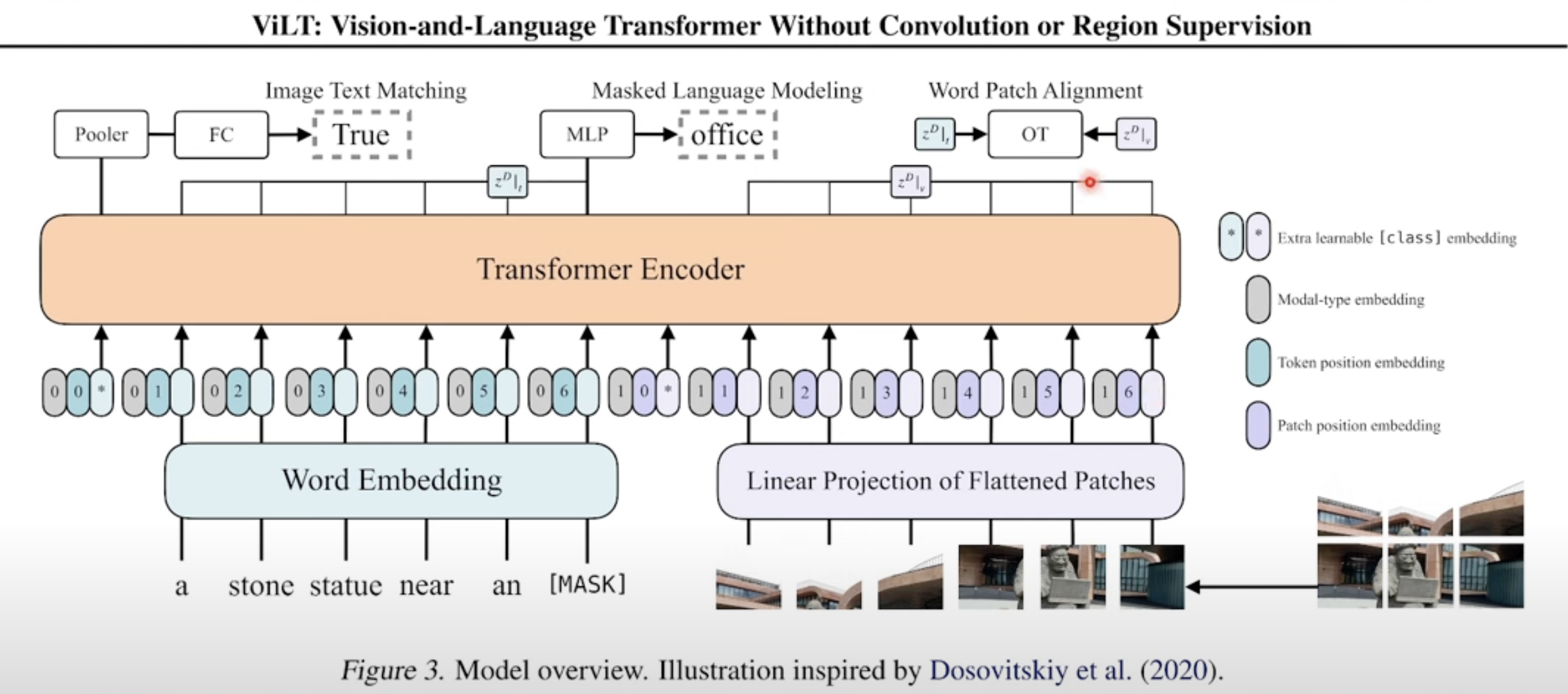
-
LlaVa Large Language-and-Vision Assistant. I believe there will be other blogs about this paper. The key difference here is a projection matrix $W$ to map video encoding same size as the language encoding.
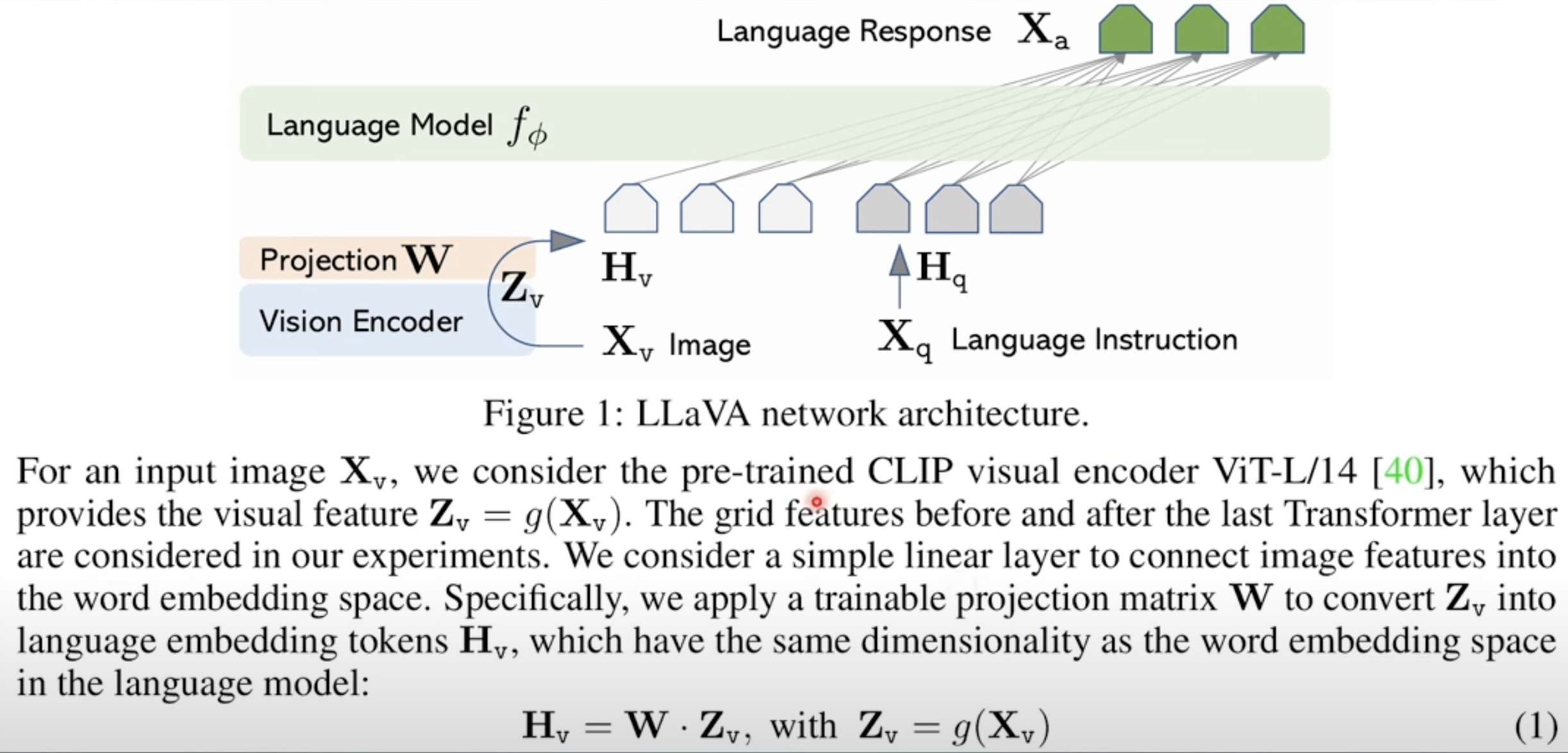
-
Summary From these two examples, we already can see these two patterns of embedding fusion. So here are the list of all 6 common patterns. The first 3 are very straightforward.
 The other three are listed below, 2 are transformer based.
The other three are listed below, 2 are transformer based.
 The last one is about creating cross attention between text and image
The last one is about creating cross attention between text and image
 and sum them together
and sum them together
