Sliding Window Attention
I was debugging a sliding window attention bug and it was fixed by this PR. I helped on the review and get it merged.
1 Sliding Attention
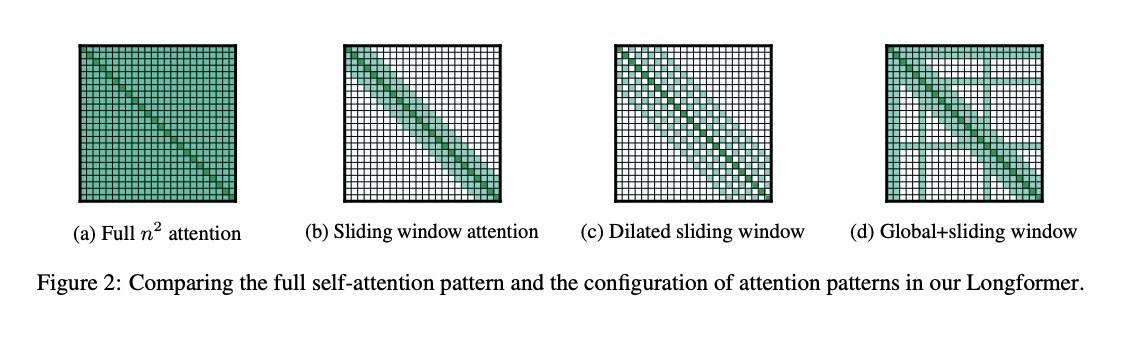
Sliding window attention is from Longformer paper is limiting the receptive field of attention layer, so each token is only getting attentions from previous w tokens.
It can also integrate w dilate concept similar to CNN.
And also combined w full/global attention for some special tokens, and local attention for the rest of the token.
2 Interleaved Sliding window
I can’t find the original paper for this idea but the concept is that one layer for full attention and one other layer for sliding window. So the implementation on HF is like following:
self.sliding_window = config.sliding_window if not bool(layer_idx % 2) else None
3 vLLM Gemma2/3
- FlashInfer backend
- Non-uniform sliding window isn’t supported for flashinfer v0 or v1. So interleaved attention is not supported
- So for interleaved attention model, like gemma2/3, Disabling sliding window and capping “the max length to the sliding window size”:
max_model_len<=sliding_window_size - To test, run
VLLM_ATTENTION_BACKEND=FLASHINFER VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 python3 examples/offline_inference/vision_language.py --model gemma3. We need to setVLLM_ALLOW_LONG_MAX_MODEL_LENbecausemax_model_lenis set larger thansliding_window_size
- Flash_Attention backend
- For interleaved attention in flashatten, when
sliding_windowis none, just setlocal_attn_masksto be none. - This is the interleaved attention version.
VLLM_ATTENTION_BACKEND=FLASH_ATTEN python3 examples/offline_inference/vision_language.py --model gemma3
- For interleaved attention in flashatten, when